Data Integration
What it is, why it matters, and best practices. This guide provides definitions, examples and practical advice to help you understand the topic of data integration.
What is Data Integration?
Data integration refers to the process of bringing together data from multiple sources across an organization to provide a complete, accurate, and up-to-date dataset for BI, data analysis and other applications and business processes. It includes data replication, ingestion and transformation to combine different types of data into standardized formats to be stored in a target repository such as a data warehouse, data lake or data lakehouse.
Five Approaches to Data Integration
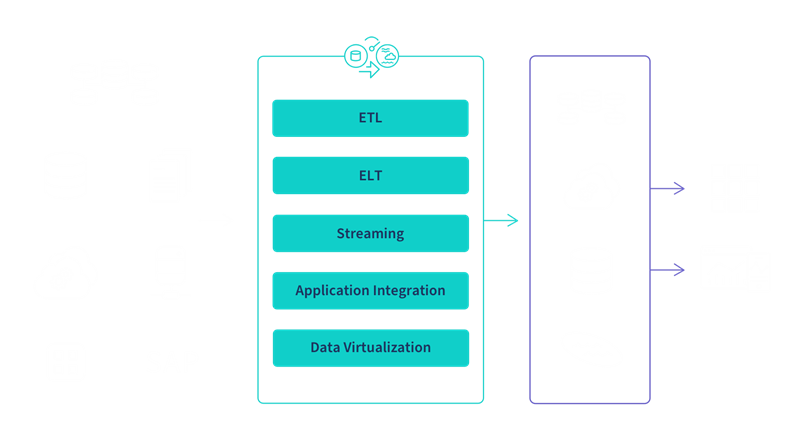
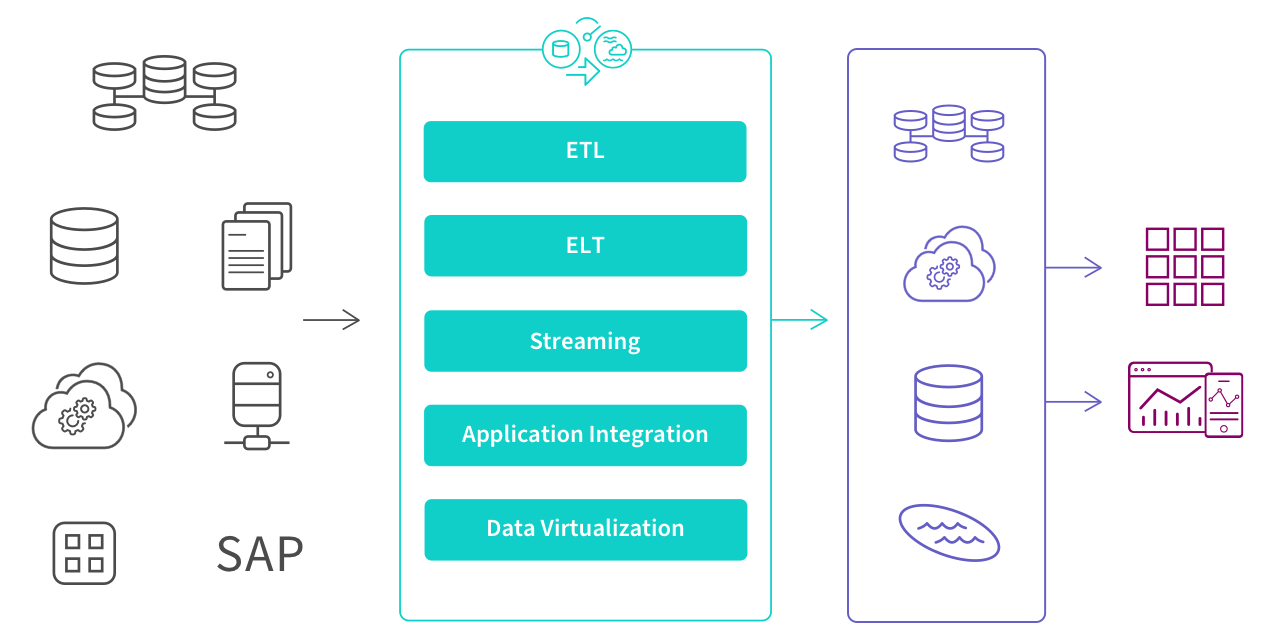
There are five different approaches, or patterns, to execute data integration: ETL, ELT, streaming, application integration (API) and data virtualization. To implement these processes, data engineers, architects and developers can either manually code an architecture using SQL or, more often, they set up and manage a data integration tool, which streamlines development and automates the system.
The illustration below shows where they sit within a modern data management process, transforming raw data into clean, business ready information.
This 2-minute video shows what data integration is and modern approaches to solving this challenge.

Below are the five primary approaches to execute data integration:
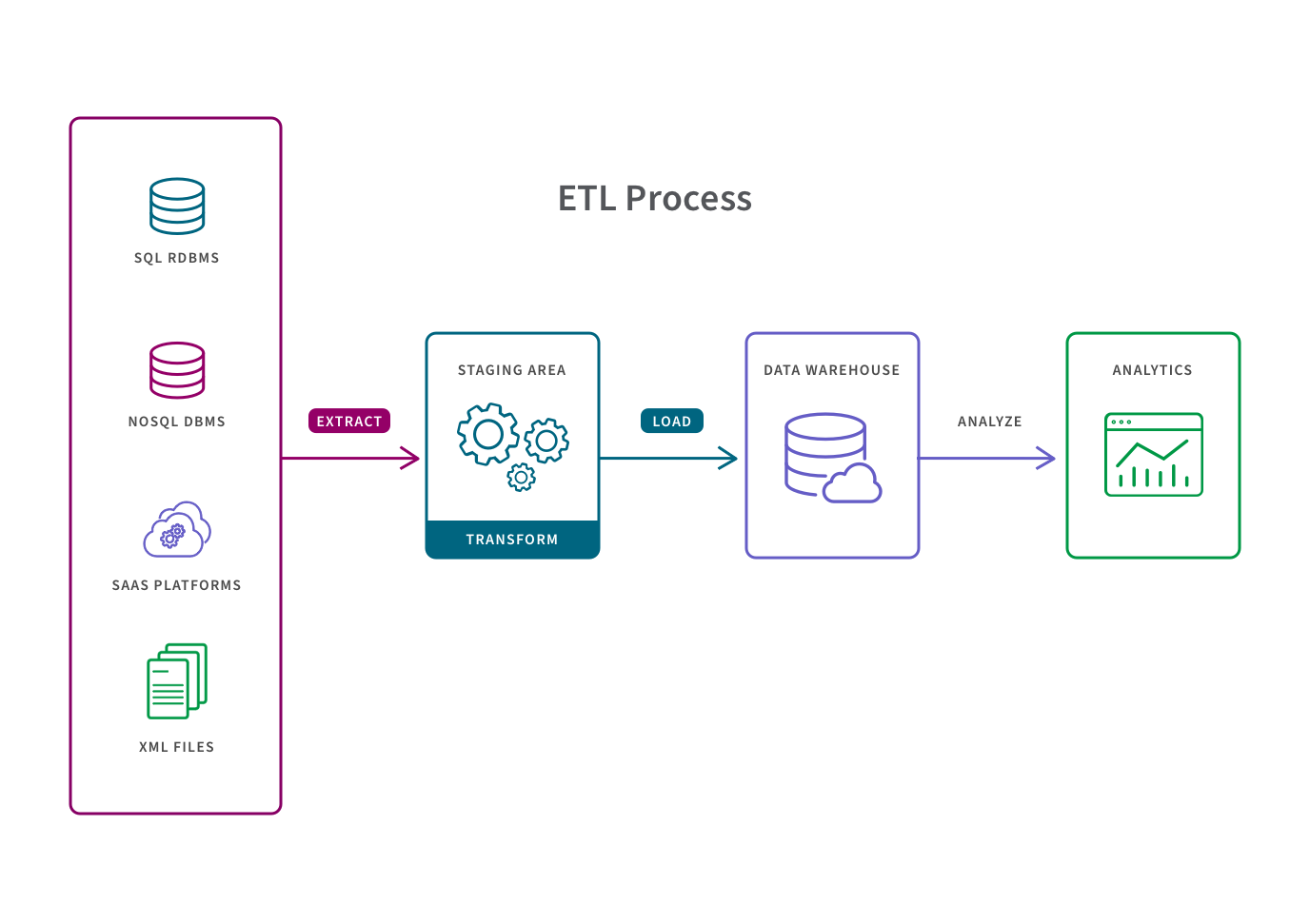
1. ETL
An ETL pipeline is a traditional type of data pipeline which converts raw data to match the target system via three steps: extract, transform and load. Data is transformed in a staging area before it is loaded into the target repository (typically a data warehouse). This allows for fast and accurate data analysis in the target system and is most appropriate for small datasets which require complex transformations.
Change data capture (CDC) is a method of ETL and refers to the process or technology for identifying and capturing changes made to a database. These changes can then be applied to another data repository or made available in a format consumable by ETL, EAI, or other types of data integration tools.
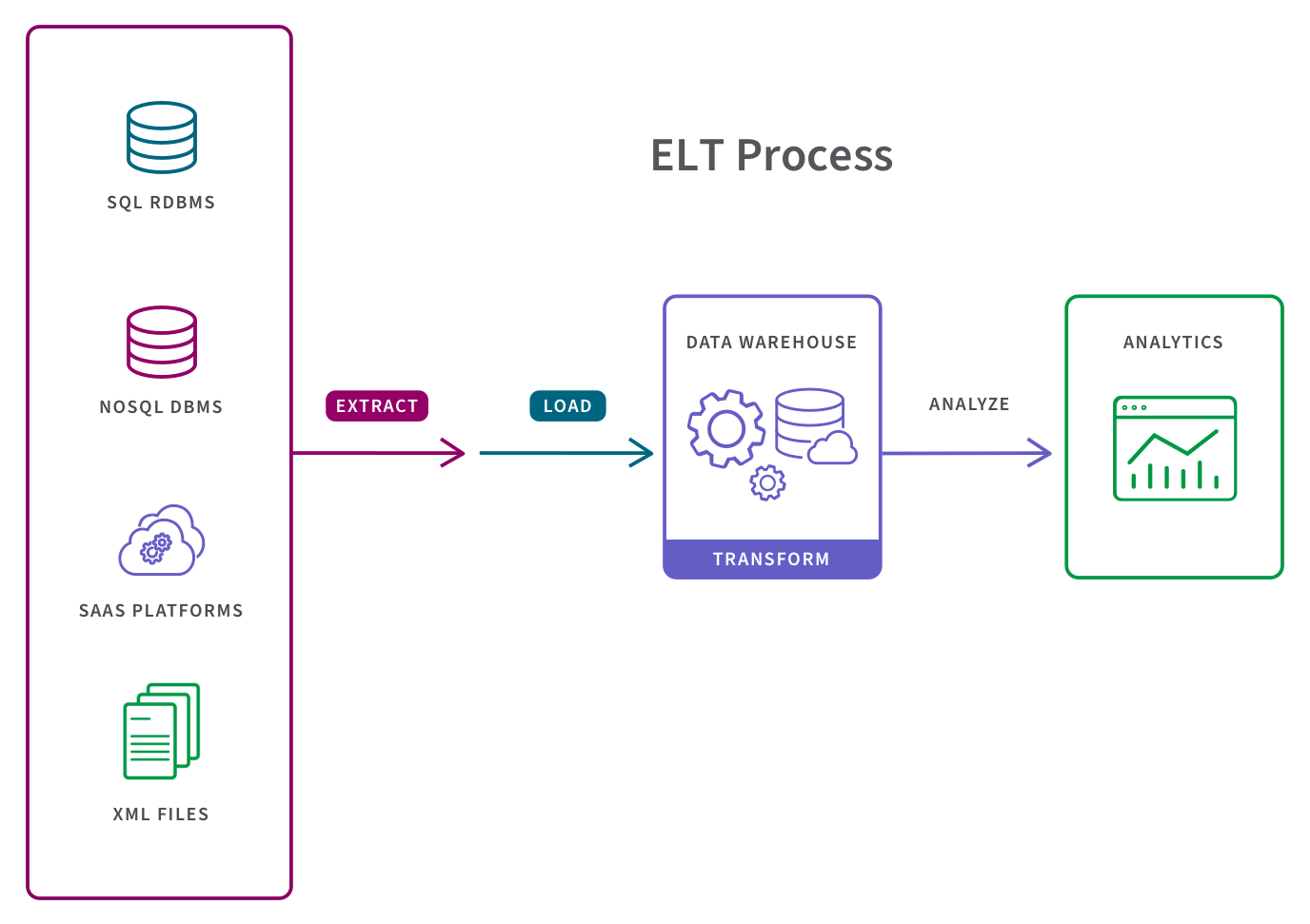
2. ELT
In the more modern ELT pipeline, the data is immediately loaded and then transformed within the target system, typically a cloud-based data lake, data warehouse or data lakehouse. This approach is more appropriate when datasets are large and timeliness is important, since loading is often quicker. ELT operates either on a micro-batch or change data capture (CDC) timescale. Micro-batch, or “delta load”, only loads the data modified since the last successful load. CDC on the other hand continually loads data as and when it changes on the source.
3. Data Streaming
Instead of loading data into a new repository in batches, streaming data integration moves data continuously in real-time from source to target. Modern data integration (DI) platforms can deliver analytics-ready data into streaming and cloud platforms, data warehouses, and data lakes.
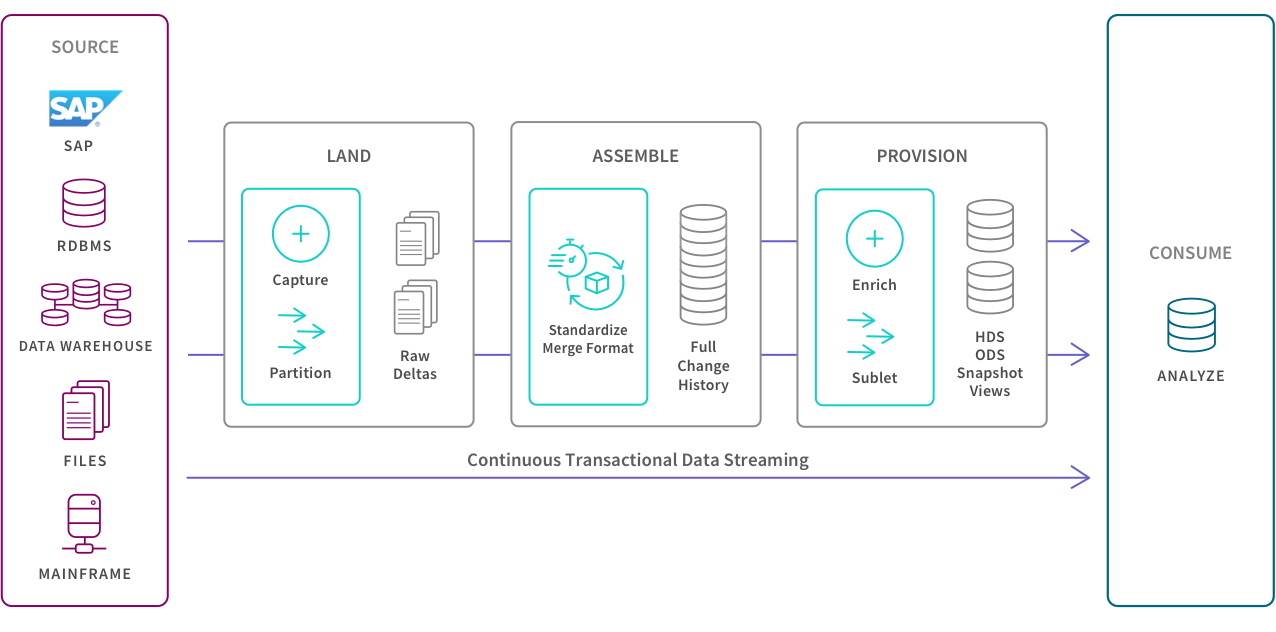
4. Application Integration
Application integration (API) allows separate applications to work together by moving and syncing data between them. The most typical use case is to support operational needs such as ensuring that your HR system has the same data as your finance system. Therefore, the application integration must provide consistency between the data sets. Also, these various applications usually have unique APIs for giving and taking data so SaaS application automation tools can help you create and maintain native API integrations efficiently and at scale.
Here is an example of a B2B marketing integration flow:
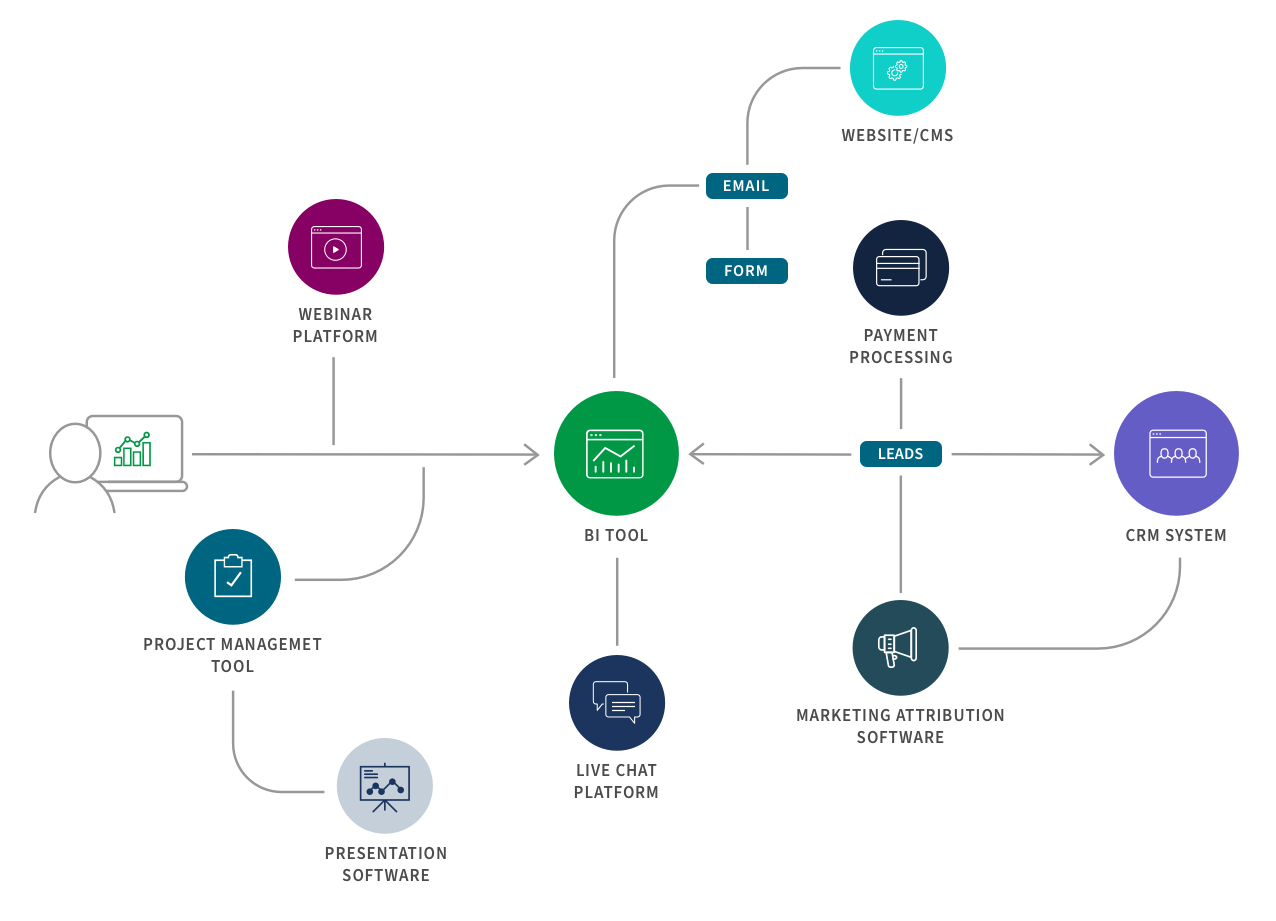
5. Data Virtualization
Like streaming, data virtualization also delivers data in real time, but only when it is requested by a user or application. Still, this can create a unified view of data and makes data available on demand by virtually combining data from different systems. Virtualization and streaming are well suited for transactional systems built for high performance queries.
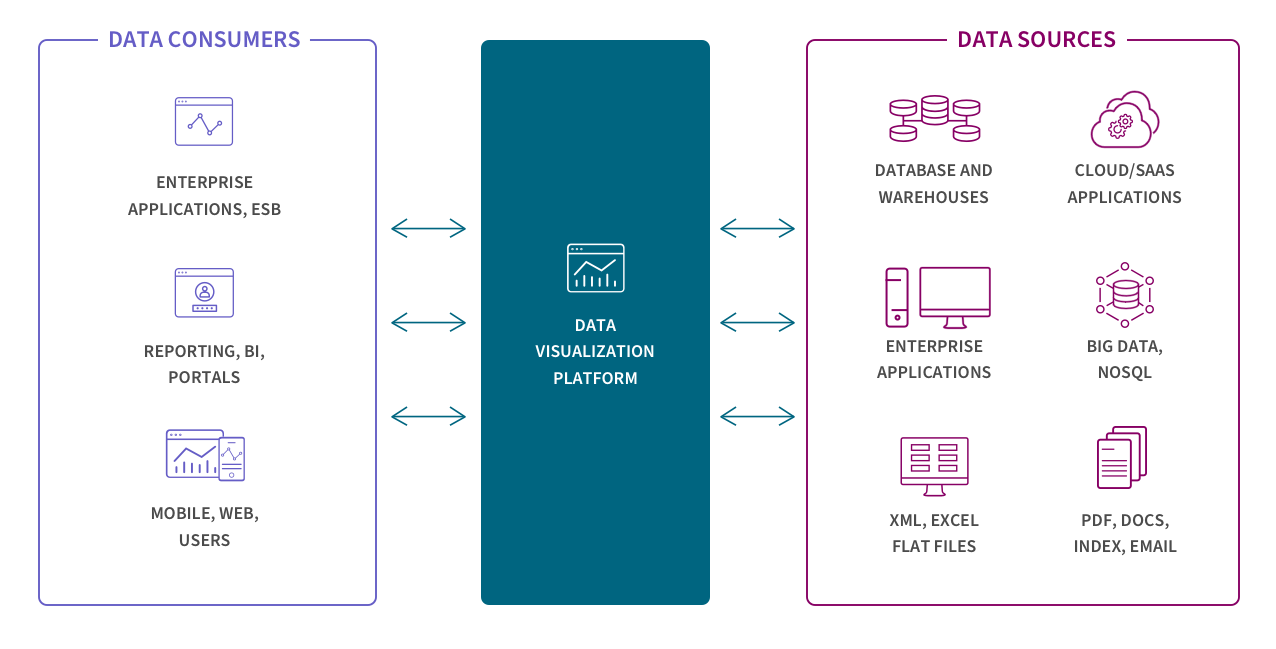
Continually evolving
Each of these five approaches continue to evolve with the surrounding ecosystem. Historically, data warehouses were the target repositories and therefore data had to be transformed before loading. This is the classic ETL data pipeline (Extract > Transform > Load) and it’s still appropriate for small datasets which require complex transformations.
However, with the rise of Integration Platform as a Service (iPaaS) solutions, larger datasets, data fabric and data mesh architectures, and the need to support real-time analytics and machine learning projects, data integration is shifting from ETL to ELT, streaming and API.
Top 4 Strategies for Automating Your Data Pipeline
4 Key Data Integration Use Cases
Here we’ll focus on the four primary use cases: data ingestion, data replication, data warehouse automation and big data integration.
Use Case #1: Data Ingestion
The data ingestion process involves moving data from a variety of sources to a storage location such as a data warehouse or data lake. Ingestion can be streamed in real time or in batches and typically includes cleaning and standardizing the data to be ready for a data analytics tool. Examples of data ingestion include migrating your data to the cloud or building a data warehouse, data lake or data lakehouse.
This diagram shows how managed data lakes automate the process of providing continuously updated, accurate, and trusted data sets for business analytics.
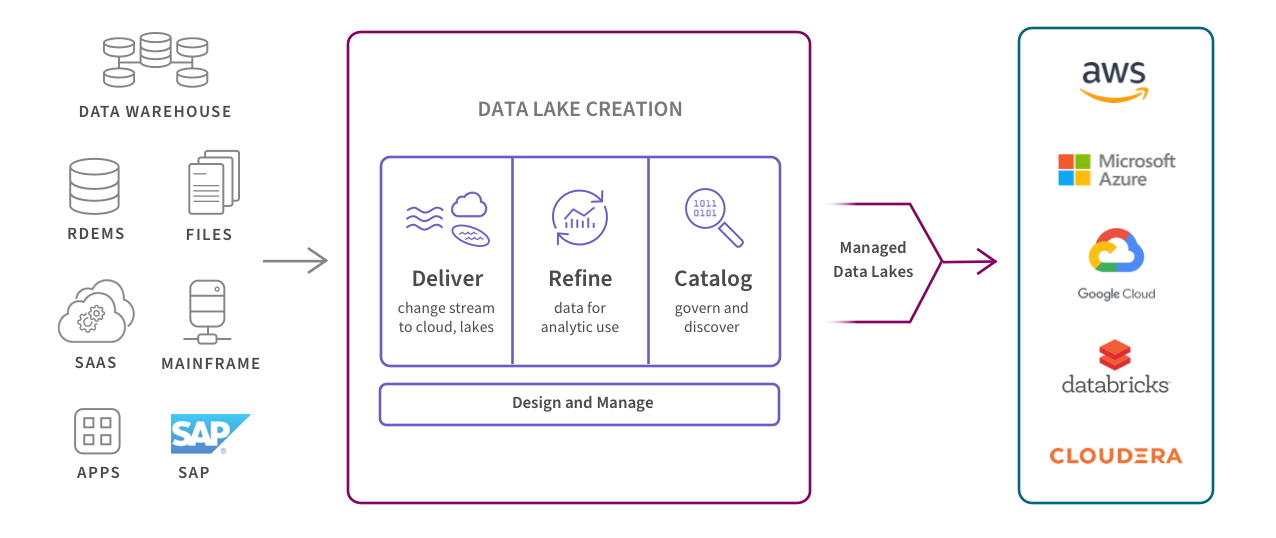
Use Case #2: Data Replication
In the data replication process, data is copied and moved from one system to another—for example, from a database in the data center to a data warehouse in the cloud. This ensures that the correct information is backed-up and is synchronized to operational uses. Replication can occur in bulk, in batches on a scheduled basis, or in real time across data centers and/or the cloud.
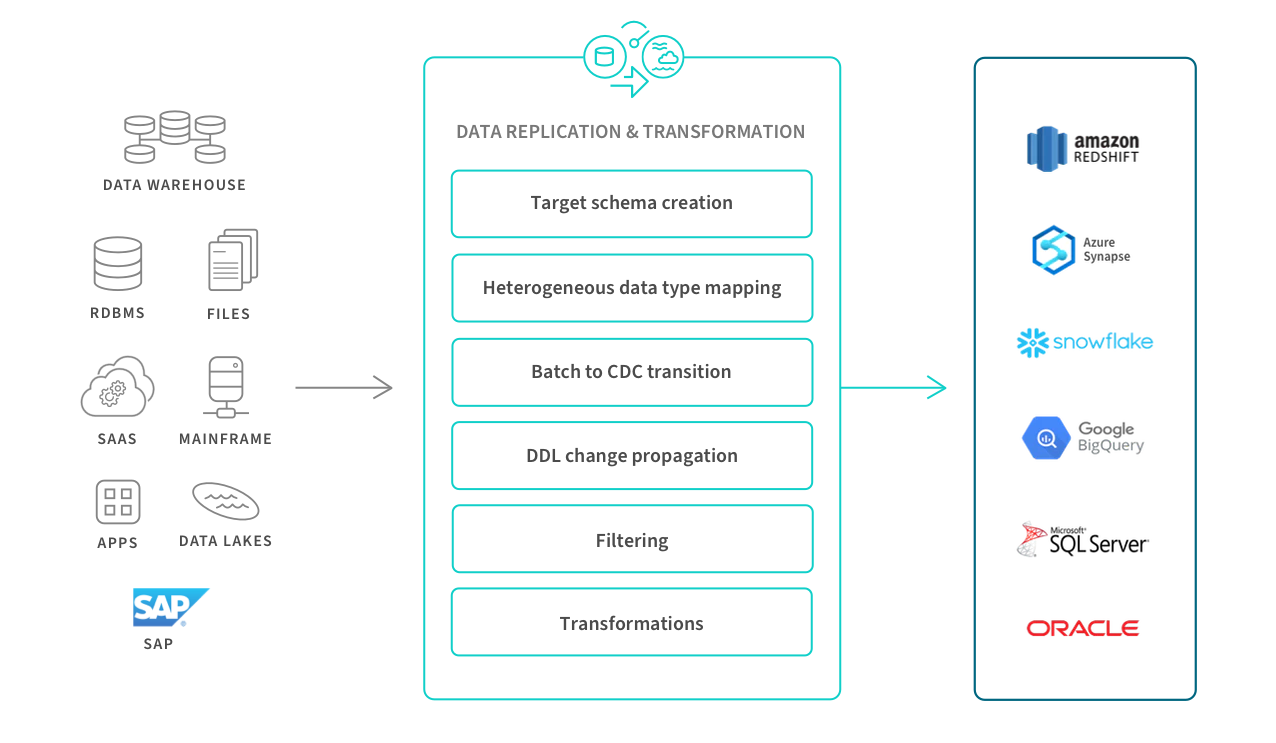
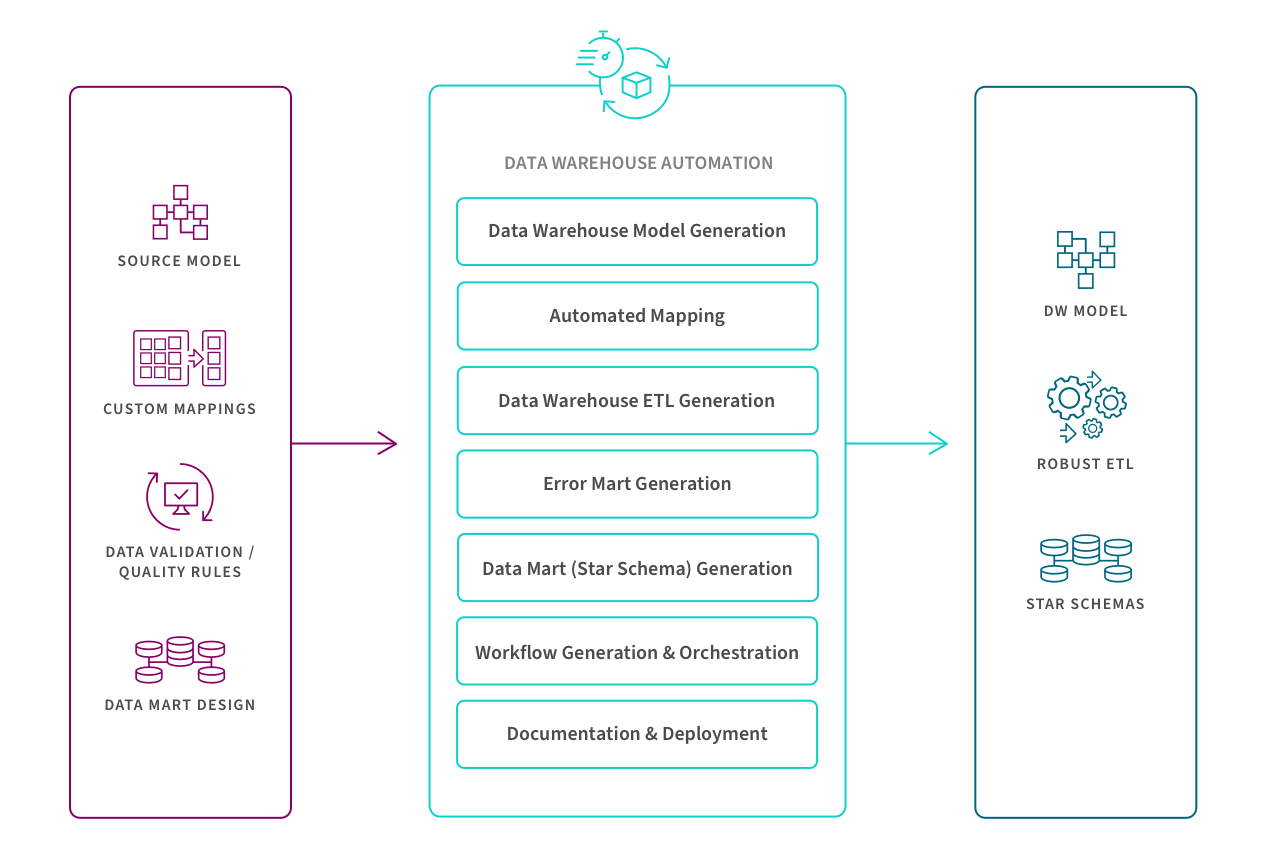
Use Case #3: Data Warehouse Automation
The process accelerates the availability of analytics-ready data by automating the data warehouse lifecycle—from data modeling and real-time ingestion to data marts and governance. This diagram shows the key steps of automated and continuous refinement to data warehouse creation and operation.
Use Case #4: Big data integration
Moving and managing the massive volume, variety, and velocity of structured, semi-structured, and unstructured data associated with big data requires advanced tools and techniques. The goal is to provide your big data analytics tools and other applications with a complete and current view of your business. This means your big data integration system needs intelligent big data pipelines that can automatically move, consolidate and transform big data from multiple data sources while maintaining lineage. It must have high scalability, performance, profiling and data quality capabilities to handle real-time, continuously streaming data.
Learn more about big data integration.
Data Governance
Data governance refers to the process of defining internal data standards and usage policies and then using technology and processes to maintain and manage the security, integrity, lineage, usability, and availability of data. A governed data catalog profiles and documents every data source and defines who in an organization can take which actions on which data. These policies and standards allow users to more easily find, prepare, use and share trusted datasets on their own, without relying on IT.
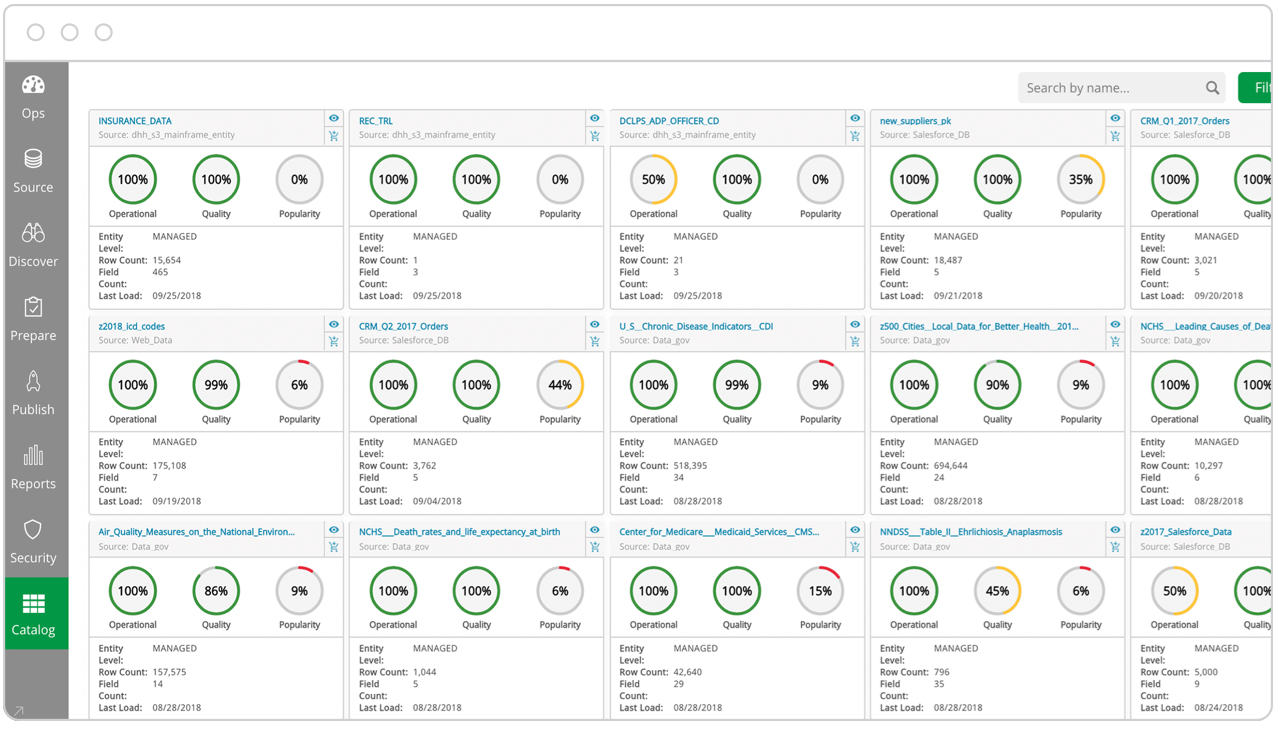
Watch how you can deliver analytics-ready data to the cloud in real-time with modern DataOps.
Data Integration Benefits
Ultimately, data integration breaks down your data silos and allows you to analyze and act upon a reliable, single source of governed data you can trust. Organizations are flooded by large and complex datasets from many different and unconnected sources—ad platforms, CRM systems, marketing automation, web analytics, financial systems, partner data, even real time sources and IoT. And unless analysts or data engineers spend countless hours preparing data for each report, all this information can’t be tied together to provide a complete picture of your business.
Data integration brings these data silos together and provides a reliable, single source of governed data that’s complete, accurate, and up-to-date. This allows analysts, data scientists and businesspeople to use BI and analytics tools to explore and analyze the full dataset to identify patterns, and then come away with actionable insights that improve performance.
Here are three key benefits of data integration:
Increased accuracy and trust: You and other stakeholders can stop wondering which KPI from which tool is correct or whether certain data has been included. You can also have far fewer errors and rework. Data integration provides a reliable, single source of accurate, governed data you can trust: “one source of truth”.
More data-driven & collaborative decision-making: Users from across your organization are far more likely to engage in analysis once raw data and data silos have been transformed into accessible, analytics-ready information. They’re also more likely to collaborate across departments since the data from every part of the enterprise is combined and they can clearly see how their activities impact each other.
Increased efficiency: Analyst, development and IT teams can focus on more strategic initiatives when their time isn’t taken up manually gathering and preparing data or building one-off connections and custom reports.
Streaming Change Data Capture
Learn how to modernize your data and analytics environment with scalable, efficient and real-time data replication that does not impact production systems.
Application Integration vs Data Integration
Application integration and data integration are closely related but there are key differences between them. Let’s review the core definitions and processes:
Application integration (API) allows separate applications to work together by moving and syncing data between them. The most typical use case is to support operational needs such as ensuring that your HR system has the same data as your finance system. Therefore, the application integration must provide consistency between the data sets. Also, these various applications usually have unique APIs for giving and taking data so SaaS application automation tools can help you create and maintain native API integrations efficiently and at scale.
Data integration (DI), as described above, moves data from many sources into a single centralized location. The most typical use case is to support BI and analytics tools. Modern DI tools and processes can handle live, operational data in real time but historically, data integration focused on moving static, relational data between data warehouses.
Create and maintain native API integrations efficiently and at scale
Learn how to move your dev team away from time-consuming, one-off development work and maintenance headaches to seamless connectivity and centralized management.
Accelerate analytics-ready data and insights with DataOps
A modern DataOps approach to data integration speeds up the discovery and availability of real-time, analytics-ready data to cloud repositories by automating data streaming (CDC), refinement, cataloging, and publishing. Some platforms also support data warehouse automation and data lake creation.
-

Real-Time Data Streaming (CDC)
Extend enterprise data into live streams to enable modern analytics and microservices with a simple, real-time and universal solution. -

Agile Data Warehouse Automation
Quickly design, build, deploy and manage purpose-built cloud data warehouses without manual coding. -

Managed Data Lake Creation
Automate complex ingestion and transformation processes to provide continuously updated and analytics-ready data lakes.