Data Modeling
What it is, types, techniques, and process. This guide provides a definition and practical advice to help you understand and practice data modeling.
Data Modeling Guide
What is Data Modeling?
Data modeling is the process of creating a diagram that represents your data system and defines the structure, attributes, and relationships of your data entities. Data modeling organizes and simplifies your data in a way that makes it easy to understand, manage, and query, while also ensuring data integrity and consistency. Data models inform your data architecture, database design, and restructuring legacy systems.
Why Is It Important?
Data modeling defines how your data will be organized, stored, retrieved, and presented. In this way, it supports business intelligence and analytics by clearly defining your data so you can find and trust the data you need.
Your organization may have many large and complex datasets from different and unconnected sources such as finance, sales, marketing, operations, and even real-time streaming data. You may also have complicated data issues such as storing your data across cloud, hybrid multicloud, on premises, and edge devices.
Data modeling helps solve for these challenges so you can:
Understand the relationships between different data elements and how they’re connected so you can better organize and manage your data.
Identify and resolve potential issues before they occur. By modeling data in advance, you can identify potential problems and address them before they cause issues in the actual implementation. You can also define schemas for existing systems by examining raw data stored in data lakes or data lakehouses.
Create a logical and efficient database structure. A well-designed data model can improve query performance and reduce data redundancy.
Facilitate data governance and communication between different teams and stakeholders. A clear and consistent model can help ensure everyone’s on the same page regarding common internal data standards and definitions.
Maintain and scale your system more easily. A well-designed model informs your data architecture design and technology selection and can make it easier to add new features or data sources in the future.
Data Model Types
As you move through your data modeling process, you’ll develop three types of models–conceptual, logical, and physical. Ideally, you’ll involve business users as well as members of your data management team. Each model builds on the previous one, becoming more complex and specific as you progress.

A conceptual data model is a simple, high-level representation of the data in your organization defined according to business requirements. It focuses on business-oriented attributes, entries, and relationships, independent of any specific technology or database management system. It caters to a specific business audience and defines the key concepts and relationships between the elements in a domain.
A logical data model is a more complex representation of the data structures and relationships within a system or your organization. It defines the entities, attributes, and relationships that make up the data, but does not specify the physical storage or implementation details. Logical models are used to communicate the conceptual design of a system to stakeholders and to guide the development of the physical data model and database. In agile DevOps or DataOps practices, this phase is sometimes skipped.
A physical data model is a detailed representation of a database design that includes information about the specific data types, sizes, and constraints of each field, as well as the relationships between tables and other database objects. It also includes information about the physical storage of your data, such as the location of files and the use of indexes and other performance optimization techniques. The physical model is used to guide the actual implementation of a database and is therefore specific to the DBMS or application software you implement.
Data Modeling Techniques
Here we describe the primary techniques used to develop data models.
Relational models are perhaps the most common model used today. They organize data in a table-like structure, with each table representing a specific entity and each row representing a specific record. They represent data in the form of tables with rows and columns, and often use SQL to manipulate the data.
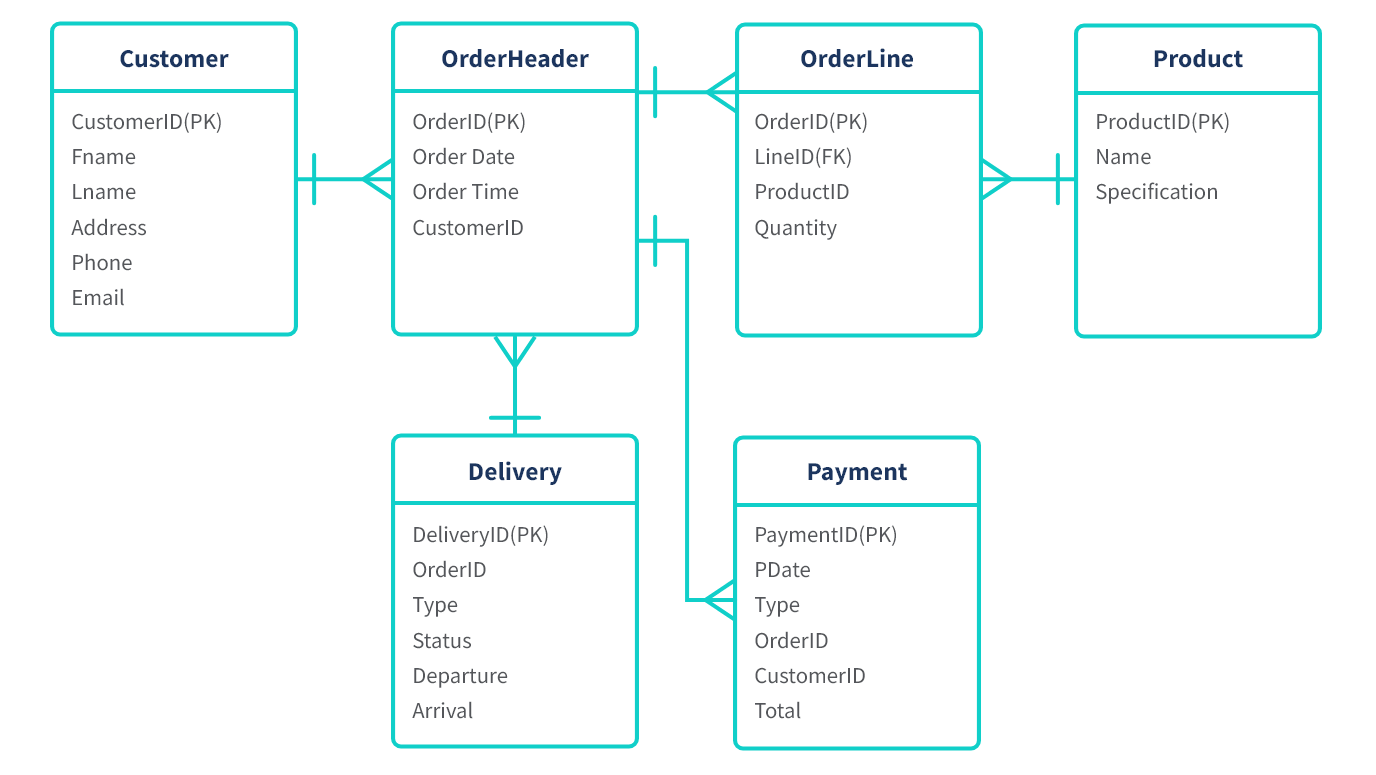
Entity-relationship (ER) models are a variation of relational models and they provide a graphical representation of entities, their attributes, and the relationships between them. Entities are objects or concepts that are relevant to the system, such as customers, orders, or products. Attributes are characteristics or properties of the entities, such as name, address, or price. As shown in the data model example below, relationships are the connections between entities, such as a customer placing an order or a product being part of a category.
Hierarchical models represent data in the form of a tree-like structure, where each record has a single parent and multiple children. They were primarily used in legacy systems and are not as popular as they once were.
Network models are similar to hierarchical models, but allow a record to have multiple parents. They are also not as widely used as they once were.
Object-oriented models are similar to ER models in that they represent data as objects with attributes and methods, but object-oriented models abstract entities into objects. As you would expect, they’re used in object-oriented programming languages such as Java and C++.
Dimensional models are based on the concept of dimensions, which are used to categorize and organize data, and facts, which are the numeric measurements or values associated with the dimensions. The dimensions are often hierarchical in nature and can be used to drill down into the data to gain insights and analyze trends. The dimensional model is designed to be easy to understand and navigate, making it a popular choice for business users and business intelligence applications. These models are typically used on OLAP systems and popular examples of dimensional models are star schemas and snowflake schemas.
Graph models represent data as nodes and edges in a graph, allowing for easy querying of relationships between data. They’re good at describing data sets that contain complex relationships and they’re used in graph databases such as JanusGraph and Neo4j.
Document models represent data as documents, with fields and values. They’re used in NoSQL databases, such as MongoDB and Couchbase.
Time-series models are used to represent time-stamped data and are widely used in IoT and financial data analysis.
Data Modeling Process

Here are the 10 steps a data modeler or data architect typically takes during the modeling process:
- Identify the Business Requirements: Make sure you understand the business requirements and the purpose of your data model. Identify the entities, attributes, and relationships that need to be represented in your model.
- Create a Conceptual Model: As described above, here you create a high-level model that represents the entities, attributes, and relationships you just identified. Use standard notation such as entity-relationship (ER) diagrams to create the model. Data modeling tools can help with creating your data model diagram.
- Normalize Your Model: Normalize your model to eliminate data redundancy and improve data integrity. Use the normalization rules such as first normal form, second normal form, and third normal form to achieve this.
- Create a Logical Model: Create a detailed data model that represents the entities, attributes, and relationships identified in step 1. As with the conceptual model, use standard notation such as ER diagrams to show how entities are connected.
- Create a Physical Model: Create a data model that represents the physical storage of your data. This includes the database schema and the data types used to store your data.
- Validate Your Model: Make sure your model meets the needs of the business and that it’s accurate and complete.
- Implement Your Model: Implement your model in a database management system. Create the database schema and load the data into the database.
- Test and Refine Your Model: Run queries and reports against your data and refine the model as needed to improve performance or fix errors.
- Document Your Model: Document your model in a way that is easily understood by others. Include detailed descriptions of the entities, attributes, and relationships in the model.
- Update Your Data Model: You’ll likely need to revise your model as your organization's business needs and data assets evolve.
Benefits
Data modeling allows stakeholders from across your company, such as business analysts, developers, and data architects, to understand the organization and relationships in your data. Other key benefits are that it will help you meet your business requirements, help you develop and implement a data architecture, and help ensure that your databases and apps are using the correct data. Here are additional benefits of data models:
- Improved data organization: They help to organize and structure data in a way that is logical and easy to understand, making it easier to access and use.
- Better data integrity: They help to ensure that data is accurate, consistent, and complete, reducing the risk of errors and inconsistencies.
- Increased scalability: They allow for the efficient management and scalability of large and complex data sets, making it easy to add or remove data as needed.
- Enhanced data security: They can help to identify and mitigate security risks, making it easier to protect sensitive data from unauthorized access.
- Better performance: They help to optimize data storage and retrieval, resulting in faster query performance and improved overall system performance.
- Improved collaboration: They can facilitate collaboration between different departments and teams, making it easier to share and access data across the organization and improve data literacy.
- Better decision-making: They can help break down data silos and ensure accurate data. Analysis of this data can provide valuable insights and information that can be used to inform strategic decision-making and business planning.
Challenges
A robust data modeling process is complicated. Carrying out the 10 steps described above isn’t fast or easy – especially if you don’t have the full support of your organization. Here are the key challenges you may face:
- Undefined Business Requirements: You must understand the business requirements and the purpose of your data model. Since your business stakeholders may not be able to fully express or even conceive their information needs, you may need to ask specific, probing questions of them.
- Lack of Support: You need business stakeholders' involvement to define requirements and provide budget. Using common business language and concepts will help them understand what you’re doing and stay engaged.
- Complexity: Data modeling can become complex when dealing with multiple relationships between entities. Try to keep your project’s scope reasonable, even as new ideas arise.
Other challenges to watch for are missing small but important data sources, overusing surrogate keys when they’re not necessary, and having poor naming standards in regards to consistency.
DataOps for Analytics
Modern data integration delivers real-time, analytics-ready and actionable data to any analytics environment, from Qlik to Tableau, Power BI and beyond.
-

Real-Time Data Streaming (CDC)
Extend enterprise data into live streams to enable modern analytics and microservices with a simple, real-time and universal solution. -

Agile Data Warehouse Automation
Quickly design, build, deploy and manage purpose-built cloud data warehouses without manual coding. -

Managed Data Lake Creation
Automate complex ingestion and transformation processes to provide continuously updated and analytics-ready data lakes.