Data Replication
What it is, why you need it, key types and examples. This guide provides practical advice to help you understand and manage data replication.
Data Replication Guide
What Is Data Replication?
Data replication is the process of creating and maintaining identical copies of data across multiple storage locations, systems, or databases in real-time or periodically. It ensures data availability, fault tolerance, and disaster recovery, allowing for better data access, redundancy, and improved system performance.
Benefits of Replicating Data
Data replication efficiently and securely moves data across heterogeneous databases, data warehouses, and big data platforms within your organization, overcoming geographical dispersion, data access demands, and complex storage challenges. This enhances database and application performance, facilitates technology integration, and enables data analytics on non-production systems, improving your overall IT infrastructure.
The brief video below describes the key concepts, benefits and challenges of data replication.

Below are the key benefits of replicating data in your organization.
Business stakeholder benefits:
- Single source of truth. Data replication helps you bring together data from different sources and repositories and lets you explore and analyze governed data. This gives you a trusted, holistic picture for analytics and helps you uncover insights that improve your business.
- Real-time data. You can access up-to-date information from the nearest or fastest replica, leading to faster response times.
- Faster insights. Get faster access to the data you need because you can use replicated data for analytical purposes such as data mining, reporting, and BI tasks without affecting production systems.
- Offline access and mobile apps: Database replication supports offline access to data and enables the functionality of mobile applications in scenarios with limited or intermittent connectivity.
IT/DataOps benefits:
- Enhanced Data Availability and Redundancy: Replication guarantees multiple data copies on different systems, mitigating data loss risks and bolstering system resilience against failures.
- Load Balancing and Performance Optimization: Distributing data across systems improves performance through load balancing, alleviating bottlenecks and optimizing resource utilization.
- Disaster Recovery and Business Continuity: Quick data recovery post-disaster minimizes downtime, ensuring uninterrupted business operations and data integrity.
- Global Data Distribution and High Application Availability: Database replication to multiple locations enables low-latency global access, while redundant data copies provide high availability and fault tolerance for critical applications.
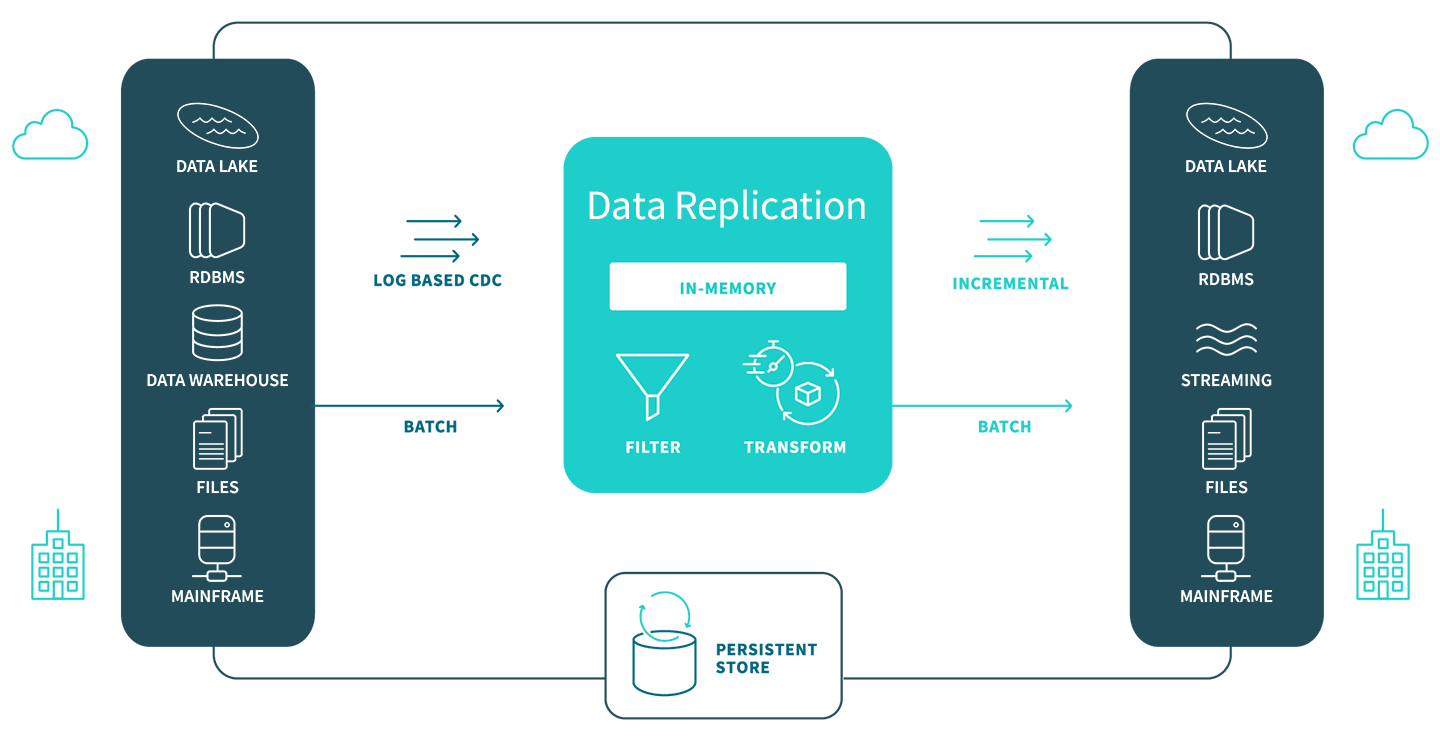
Streaming Change Data Capture
Learn how to modernize your data and analytics environment with scalable, efficient and real-time data replication that does not impact production systems.
Data Replication Types
Various data replication strategies offer you diverse approaches for maintaining consistent and distributed data across multiple sites. These strategies encompass methods such as duplicating entire databases, replicating changes incrementally, creating periodic snapshots, and enabling bidirectional updates among multiple databases. Here are the key types of data replication:
Transactional replication captures and synchronizes individual data transactions in real-time, ensuring that changes made to the source database are precisely mirrored in the target database, maintaining data consistency and integrity.
Snapshot replication periodically creates point-in-time copies or snapshots of the source database and replicates these snapshots to the target, allowing for less frequent updates but potentially higher data transfer efficiency.
Merge replication combines changes made in both the source and target databases, allowing bidirectional synchronization of data between systems and supporting scenarios where updates occur in multiple locations.
Key-based replication involves replicating data based on specific key fields, such as unique identifiers, to identify and transfer only the relevant data changes, optimizing replication efficiency.
Peer-to-peer replication is a type of data synchronization where multiple geographically distributed databases actively serve read and write requests independently, ensuring high availability and low-latency access to data for users across different locations. Conflict-free replicated data types (CRDTs) are data structures and algorithms optimized for distributed systems, enabling automatic conflict resolution in scenarios with concurrent updates across replicas, ensuring consistency without centralized coordination. This ensures coherent data across replicas, even during network partitions or simultaneous updates.
Synchronous replication immediately commits changes to both the source and target databases, ensuring strong data consistency but potentially causing performance overhead.
Asynchronous replication allows some delay between changes being made and replicated, offering higher performance but potentially leading to eventual consistency discrepancies.
Replication Schemes
There are two main types of schemes: one-time projects and ongoing processes. Replicating data usually falls into the latter category, necessitating frequent data copying to ensure updates from one source are propagated across the entire system.
The three primary techniques for replication are full, incremental, and log-based replication. Each method has its own set of pros and cons, and the key challenge lies in striking a balance between data consistency and system performance. Selecting the appropriate approach will largely depend on your intended use for the replicated data, the data volume, and the storage method employed.
1. Full-table replication involves the complete duplication of all existing, new, and updated data from the primary data repository to the target, and in some cases, to each site within your distributed system.
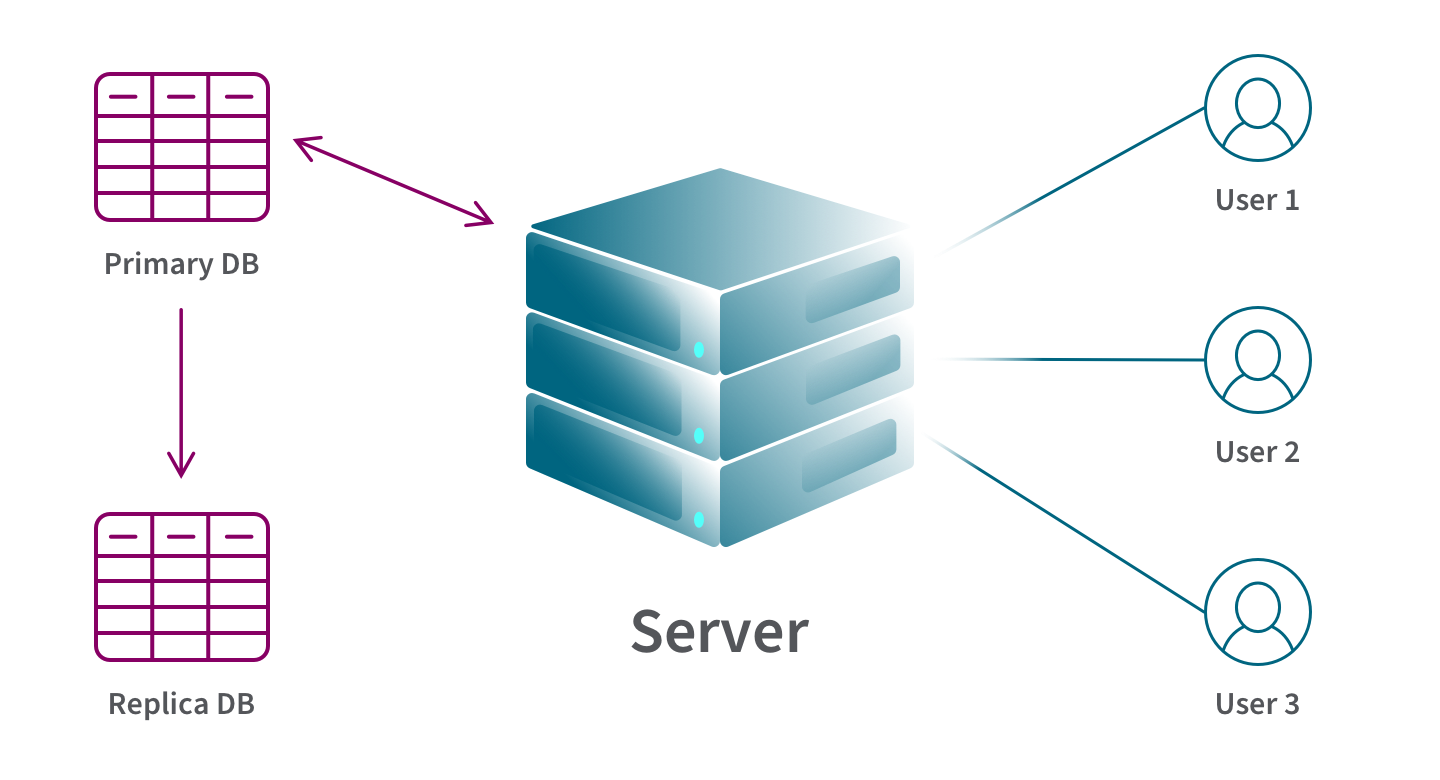
Pros: The technique offers several benefits. First, it ensures higher data availability as a replicated database guarantees data redundancy even if one of the sites fails. Second, it enables faster queries due to localized processing. Additionally, if key-based replication is not viable in the primary database or if data records are frequently hard deleted, employing a full-table is a suitable alternative.
Cons: Full-table database replication comes with certain drawbacks. Primarily, it can lead to increased network bandwidth loads and require additional processing power, resulting in higher costs. Moreover, achieving concurrency becomes more challenging, and the update process slows down significantly, as each individual update must be executed across all sites in the distributed system.
2. Key-based incremental replication relies on a specific replication key column in the primary data repository to identify updated and new data. It selectively updates data in the replica databases that have changed since the last update. Commonly, this key is represented by a timestamp, datestamp, or an integer.
Pros: Key-based replication provides heightened efficiency as only the modified data rows are copied during each update.
Cons: Key-based replication cannot detect and replicate data that has been hard-deleted in the source. This is because when a record is deleted in the primary database, the corresponding key value is also deleted.
3. Log-based incremental replication operates by copying data according to the content of the database's binary log file. This log file contains crucial details about alterations in the primary database, including inserts, updates, and deletes. The majority of database vendors offer support for this method, with notable examples being MySQL, PostgreSQL, Oracle, and MongoDB.
Pros: This technique stands out as the most efficient among the three options, particularly when the structure of your primary database remains relatively constant. Log-based incremental database replication offers the advantage of capturing granular changes in your database, such as inserts, updates, and deletes, directly from the binary log file. This results in highly efficient and accurate replication of data across distributed systems.
Cons: A potential drawback of log-based incremental replication is its sensitivity to changes in your database's structure, which could lead to compatibility issues. Additionally, the reliance on binary log files might require careful management to ensure proper synchronization and avoid data inconsistencies.
Change Data Capture in Data Replication
Replicating data in a low-impact way while trying to handle real-time change streams is complex. Below are the four main options to process captured data changes:
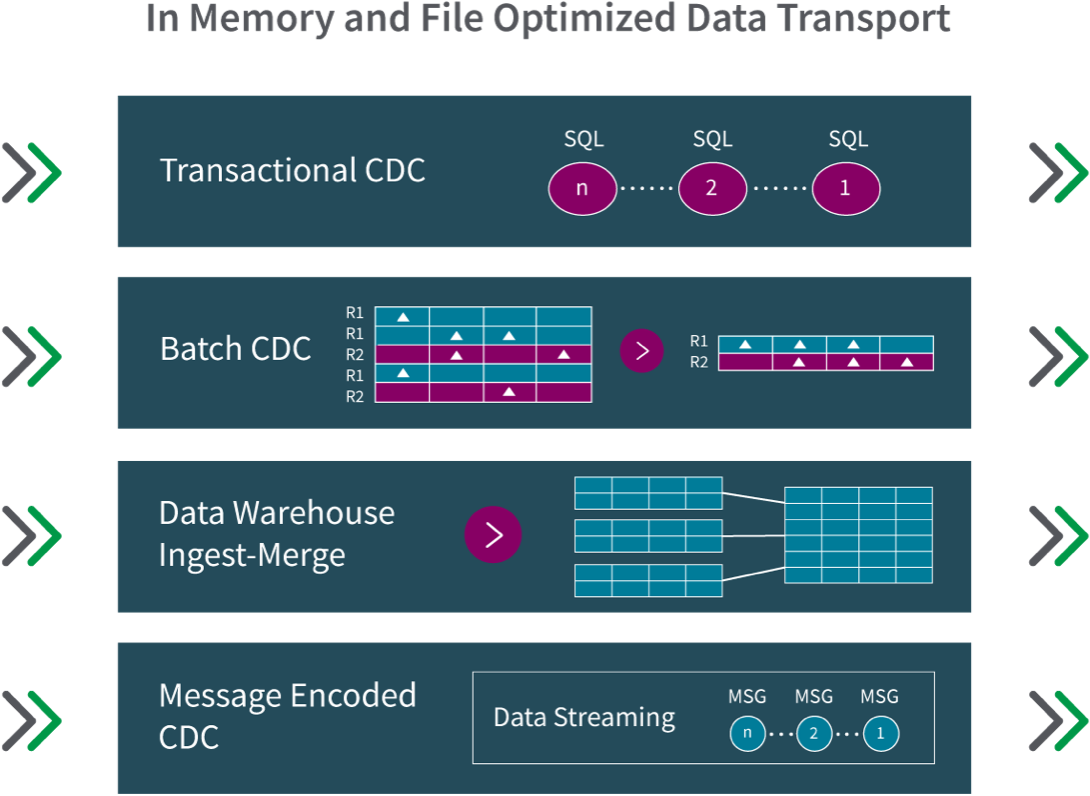
- Transactional CDC ensures low latency and strict referential integrity by applying transactions in the order they were committed to the primary database.
- Batch-Optimized CDC groups transactions into batches, optimizing ingestion and merging into data warehouses both on-premises and in the cloud.
- Data Warehouse Ingest-Merge enables loading with native performance-optimized APIs for Snowflake, Azure Synapse, and other EDWs that utilize massively parallel processing.
- Message-Encoded CDC, also known as Message-Oriented Data Streaming, allows capturing and streaming data change records into message broker systems like Apache Kafka.
Data Replication Software
Data replication tools facilitate the migration and transfer of your enterprise data between data centers, offering you a unified management system for continuous oversight and seamless business continuity.
You have the option to utilize either the data replication software offered by your database vendor (such as Oracle Database or Microsoft SQL) or opt for a third-party replication tool. The key benefits of leading third-party solutions lie in their flexibility and efficiencies. They’re database-agnostic, enabling you to seamlessly replicate data across various types of databases within your environment.
Learn more:
Challenges
Here are the key challenges you’ll face as you replicate data across your system:
- Data Consistency: Ensuring that replicated data remains consistent across all sites and avoids discrepancies or conflicts.
- Network Latency: Dealing with delays in data transmission across distributed locations, affecting real-time updates (see the CDC section above).
- Conflict Resolution: Managing conflicts that arise when the same data is updated simultaneously on different replicas.
- Data Security: Maintaining data confidentiality and integrity during the replication process to prevent unauthorized access or tampering.
- Synchronization Complexity: Overcoming the complexities of synchronizing data across different databases, schemas, and versions.
- Scalability: Adapting replication strategies to accommodate growing data volumes and expanding infrastructure.
- Operational Overhead: Balancing the resources required for replication against system performance and maintenance costs.
Frequently Asked Questions
What is the purpose of data replication?
The purpose of data replication is to ensure data availability, resilience, and consistency across multiple locations or systems. It serves to enhance fault tolerance, support disaster recovery, improve performance through load balancing, enable global data distribution, and provide redundancy for critical applications, ultimately contributing to efficient business operations and data integrity.
What is an example of data replication?
An example of data replication is when an e-commerce company maintains multiple copies of its customer database across different data centers. Whenever a new order is placed or customer information is updated, these changes are automatically synchronized across all copies, ensuring consistent data availability, supporting disaster recovery, and allowing users to access the most up-to-date information regardless of their geographical location.
What are the methods of data replication?
Data replication can be achieved through methods like full replication, where entire databases are duplicated across systems, and incremental replication, which copies only the changes made since the last synchronization, ensuring efficient data distribution and management. Other variations include snapshot replication, peer-to-peer replication, master-slave replication, multi-master replication, log-based replication, key-based replication, cross-database replication, and geographic replication.
Where is data replication used?
Data replication is used in various scenarios, such as distributed database systems, disaster recovery setups, high availability configurations, multi-site applications, global content delivery networks, and situations requiring efficient data synchronization across geographically dispersed locations.
What is the difference between data replication and data backup?
Data replication and data backup, also referred to as mirroring, are frequently conflated, but they’re distinct procedures. Mirroring constitutes a type of replication wherein a complete database backup is preserved as a precautionary measure against primary database failures. As previously explained, replication primarily concerns database objects and is generally aimed at enhancing operational efficiency and bolstering data availability.