
Data Lake
What it is, key features, and benefits. This guide provides a data lake definition and practical advice to help you understand what it is and how it differs from a data warehouse as you evaluate the best storage strategy for your organization.
What is a Data Lake?
A data lake is a data storage strategy whereby a centralized repository holds all of your organization's structured and unstructured data. It employs a flat architecture which allows you to store raw data at any scale without the need to structure it first. Instead of pre-defining the schema and data requirements, you use tools to assign unique identifiers and tags to data elements so that only a subset of relevant data is queried to analyze a given business question. This analysis can include real-time analytics, big data analytics, machine learning, dashboards and data visualizations to help you uncover insights that lead to better decisions.
Data Lake Architecture
There are a number of different tools you can use to build and manage your data lake, such as Azure, Amazon S3 and Hadoop. Therefore, the detailed physical structure of your system will depend on which tool you select. Still, you can see below how it can fit into your overall data integration strategy.
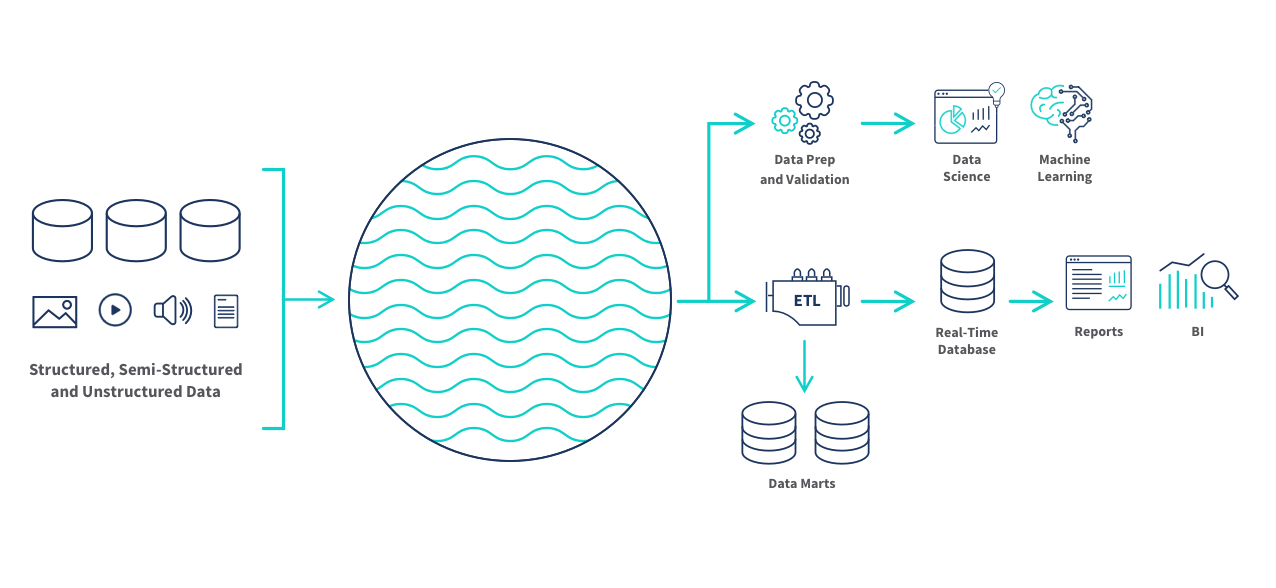
Data teams can build ETL data pipelines and schema-on-read transformations to make data stored in a data lake available for data science and machine learning and for analytics and business intelligence tools. As we discuss below, managed data lake creation tools help you overcome the limitations of slow, hand-coded scripts and scarce engineering resources.
Learn more about data lake architecture.
Cloud Data Lake Comparison Guide
Get an unbiased, side-by-side look at all the major cloud data lake vendors, including AWS, Azure, Google, Cloudera, Databricks, and Snowflake.
Data Lake Benefits
Because the large volumes of data are not structured before being stored, skilled data scientists or end-to-end self-service BI tools can provide you access to a broader range of data far faster than in a data warehouse. Six key advantages include:
- Agility. You can easily configure queries, data models, or applications without the need for pre-planning. In addition to SQL queries, the data lake strategy is well suited to support real-time analytics, big data analytics, and machine learning.
- Real-time. You can import data in its original format from multiple sources in real-time. This allows you to perform real-time analytics and machine learning and trigger actions in other applications.
- Scale. Because of its lack of structure, data lakes can handle massive volumes of structured and unstructured data such as ERP transactions and call logs.
- Speed. Keeping data in a raw state also makes it available for use far faster since you don’t have to perform time-intensive tasks such as transforming the data and developing schemas until you define the business question(s) that need to be addressed.
- Better insights. You can gain unexpected and previously unavailable insights by analyzing a broader range of data in new ways.
- Cost savings. Data lakes have lower operational costs since they’re less time-consuming to manage. Also, storage costs are less expensive than traditional data warehouses because most of the tools you use to manage them are open source and run on low-cost hardware.
Data Lake vs Data Warehouse
Many organizations employ both strategies to cover their data storage needs. Some choose to combine key capabilities of each by implementing a data lakehouse. Here are the six main differences between data lake vs data warehouse:
| Data Lake | Data Warehouse | |
|---|---|---|
| 1. Processing |
ELT (Extract, Load, Transform). Data is extracted from its source(s), loaded into the lake, and is structured and transformed only when needed.
|
ETL (Extract, Transform, Load). Data is extracted from its source(s) and then scrubbed and structured before loading into a repository.
|
| 2. Storage |
Contains all of your organization's data in both a structured and raw, unstructured form.
|
Contains only structured data which has been cleaned and processed based on predefined business needs.
|
| 3. Schema |
Schema is defined after the data is stored. This makes the process of capturing and storing the data faster.
|
You have to define schema before the data is stored. This lengthens the time it takes to process the data, but once complete, the data is available for immediate use.
|
| 4. Users |
Data is typically used by data scientists and engineers who prefer to study data in its raw form.
|
Data is typically accessed by managers and business-end users looking to answer pre-determined questions.
|
| 5. Analysis |
Predictive analytics, machine learning, data visualization, dashboards, BI, big data analytics.
|
Data visualization, dashboards, BI, data analytics.
|
| 6. Expense |
Storage costs are typically lower than a data warehouse. Plus, operational costs are lower since data lakes take less time to manage.
|
Data warehouses cost more and also require more time to manage, resulting in additional operational costs.
|
Dive deeper on comparing data lake vs data warehouse.
Managed Data Lake Creation
The main challenge in deploying a data lake strategy is that traditional data integration processes are limited by slow, hand-coded scripts and scarce engineering resources. A fully automated approach to end-to-end data lake creation accelerates your ROI.

Managed data lake creation automates your entire data lake pipeline, from real-time ingestion to processing and refining raw data and making it accessible to consumers. The best solutions provide the following:
- Allow you to easily build and manage agile data pipelines with support for all major data sources and cloud targets without writing any code.
- Zero-footprint change data capture technology delivers data in real-time without impacting your production systems.
- End-to-end lineage, so you can fully trust your data.
- A secure enterprise-scale data catalog provides data consumers with a governed data marketplace to search, understand and shop for curated data.
Accelerating the utility of your data lake in these ways helps you establish active intelligence, a state of continuous awareness driving real-time, actionable insights based on the very latest data.
3 Ways to Increase Your Data Lake ROI
DataOps for Analytics
Modern data integration delivers real-time, analytics-ready and actionable data to any analytics environment, from Qlik to Tableau, Power BI and beyond.
-

Real-Time Data Streaming (CDC)
Extend enterprise data into live streams to enable modern analytics and microservices with a simple, real-time and universal solution. -

Agile Data Warehouse Automation
Quickly design, build, deploy and manage purpose-built cloud data warehouses without manual coding. -

Managed Data Lake Creation
Automate complex ingestion and transformation processes to provide continuously updated and analytics-ready data lakes.