Data Mesh
What it is, why you need it, and best practices. This guide provides definitions and practical advice to help you understand and establish a data mesh architecture in your organization.
What Is A Data Mesh?
Data mesh refers to a data architecture where data is owned and managed by the teams that use it. A data mesh decentralizes data ownership to business domains–such as finance, marketing, and sales–and provides them a self-serve data platform and federated computational governance. This allows different domains to develop, deploy, and operate data services more autonomously and model their data based on their specific needs while also ensuring a consistent and unified data experience across your organization.
Four Core Principles
The data architect Zhamak Dehghani first defined the term data mesh in 2019. The word “mesh” refers to the way in which domains can easily use data products from other domains and how data from multiple domains can be combined to get a more holistic view.
Dehghani based the approach on the four core principles described below. These principles enable scale and agility while also ensuring data quality and data integrity across your organization.
1) Domain-oriented, decentralized data ownership and architecture. This principle states that business domains such as customer service, operations, marketing, and sales develop, deploy, and manage their own analytical and operational data services. This allows each functional area to model their data based on their specific needs.
2) Data as a product. This principle requires the domain teams to think of other domains in your organization as consumers and to support their needs. This means ensuring high-quality, secure, up-to-date data.
3) Self-service data infrastructure as a platform. According to this principle, your organization should have a dedicated infrastructure engineering team that provides the tools and systems for each domain team to consume data from other domains and to autonomously develop, deploy, and manage data products that are interoperable across all domains.
4) Federated computational governance. This principle states that while you must have a centralized data governance authority, you should also embed governance issues within the processes of each domain. This way, each domain has autonomy and can move quickly while also adhering to organizational and governmental rules.
Data Mesh Architecture
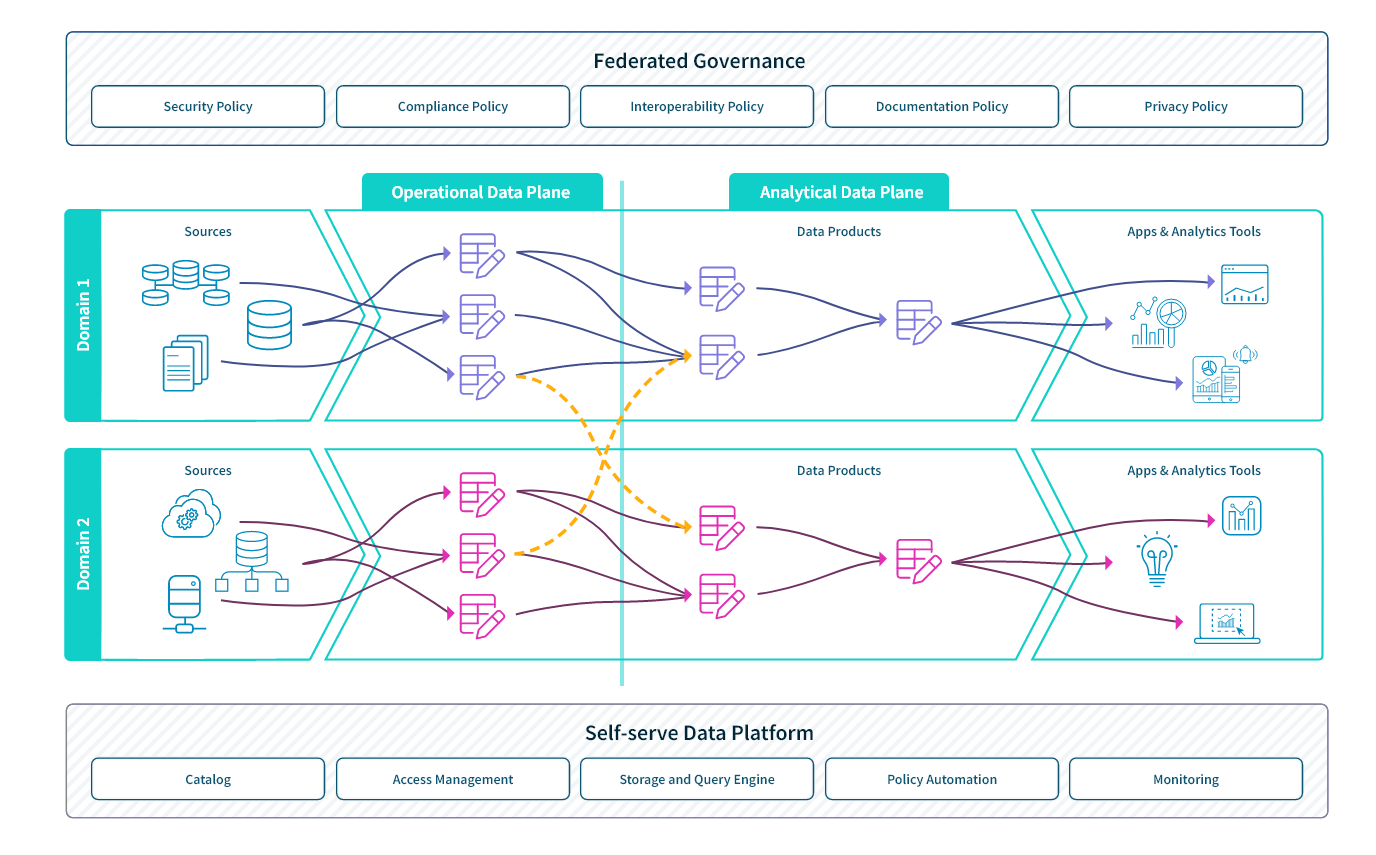
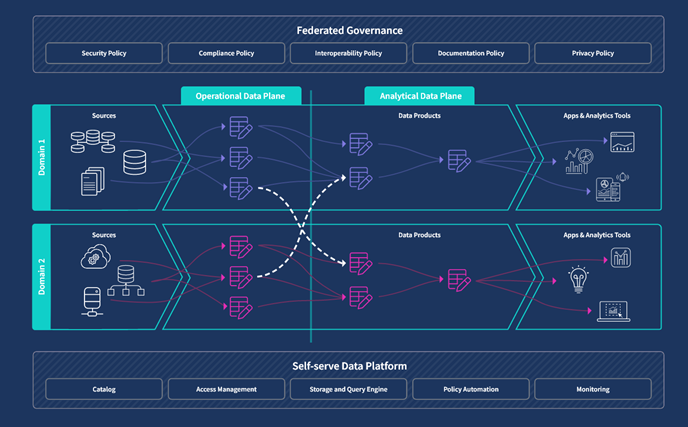
This logical architecture diagram shows how two domain teams leverage this model. Let’s use this diagram from the perspective of Domain Team 1 to highlight the key features of this model.
- Domain Team 1 ingests data from sources such as transactional, supply chain, and CRM applications into the operational data plane (or category).
- Team 1 builds data models in the analytical data plane. These models are data products used to perform the analysis needs of Domain 1. Team 1 may also choose to publish these data products, making them available to other domains.
- The orange color lines represent the interoperability of the model. Multiple data products can come together to support a use case such as business intelligence and a single data product can serve multiple use cases.
- Federated governance embeds within the processes of each domain governance policies such as interoperability, documentation, security, privacy, and compliance.
- The self-service data platform provides the foundation for the model. It provides the domain teams with key capabilities such as a storage and query engine, a data catalog, access management, monitoring, and policy automation.
Benefits
Data meshes are not for everyone. For example, if your organization’s data needs are small and your data needs don’t change much over time, this architecture would add unnecessary complexity.
But, if your organization has a high degree of change and uncertainty in your data needs and you have multiple business domains, each with their own data use cases and types of transformations, here are the key benefits you’ll enjoy:
Less bottleneck. Your centralized data team can easily become a bottleneck for you. This is because it’s usually distracted by complex infrastructure issues like repairing broken data pipelines. And then when it can find time to focus on providing insights, it has to locate the necessary domain data and quickly gain specific domain expertise to give meaningful insights.
Faster data processing. Distributing your data pipeline across domains reduces the technical strain on your data lake or data warehouse. Plus your data platform team can also provide APIs to domains and thereby reduce the volume of individual requests.
Data democratization. The self-service nature of the data platform not only makes it easier for developers, data scientists, and data engineers to access data, it enables business users from each domain to find and explore the data they need and gain insights faster.
Compliance and security. The decentralized mesh model requires that access control be applied for each domain-oriented data product. This brings stronger governance practices and ensures that your organization adheres to government regulations. Log and trace data ensures observability into your system and allows auditors to know who accessed what data and how often.
Cost efficiency. Many organizations adopting this new model are also switching to cloud data warehouses and streaming data pipelines to collect real-time data. The cloud infrastructure lowers your operational costs because you can add large clusters only as you need them and pay only for the storage you use.
Interoperability: The centralized governance and standardization of this architecture requires domain teams to apply consistent rules when they structure their datasets and to support data linkage across domains. This consistency allows data consumers to use simple APIs to access data products from across your organization.
Data Mesh vs Data Lake
At a conceptual level, the main difference is that a data lake refers to a technology approach to centrally store data whereas a data mesh flips this model on its head and refers to both organizational and technological issues for a decentralized system of interoperable data products. Let’s dig a bit deeper…
A data lake is a centralized repository managed by a central data team that holds all of your organization's structured and unstructured data.
- Pros: The benefit of this flat architecture is that it allows you to efficiently store raw data at any scale without the need to structure it first. And if your organization’s data needs are small and your data needs don’t change much over time, your central team can meet the needs of the business in terms of analytics, machine learning, and other applications.
- Cons: Your central data team can quickly become a bottleneck if your organization’s data needs change frequently and you have multiple business domains that each have their own data use cases and types of transformations. Your data team will often be distracted by infrastructure issues and when they do try to provide insights, they have to locate the necessary domain data and acquire specific domain expertise. Data lakes can also become data swamps because they can lack data quality and data governance practices to provide reliable insights.
In a data mesh architecture, data is organized by its domain as shown in the architecture diagram in the section above. This greatly reduces the bottleneck issue and makes data more easily accessible to all users across your organization. You may still deem it necessary for a domain to have its own data lake, but it would be just a node on the mesh, an implementation issue, rather than the focus of your overall architecture.
Data Mesh vs Data Fabric
The concepts of data mesh vs data fabric are often confused. The key difference between them is that a data fabric architecture doesn’t emphasize decentralization and organizing data by its domain.
Data fabric refers to a machine-enabled data integration architecture that utilizes active metadata assets to unify, integrate, and govern disparate data environments. By standardizing, connecting, and automating data management practices and processes, data fabrics improve your data security and accessibility and provide end-to-end integration of data pipelines and on premises, cloud, hybrid multicloud, and edge device platforms.
Still, a data fabric would be complementary to your data mesh model because it can automate important activities like enforcing global governance, creating data products, and combining multiple data products.
Implementation
Moving from a centralized data platform to an ecosystem of data products will require you to overhaul the people, processes, and technology of your data team.
People: Implementing a data mesh is primarily an organizational change; shifting data responsibilities to the business domains. So, to manage the distributed data products, each domain will need its own cross-functional team including data engineers and data product owners. And, your central data team must shift to become a data platform team that provides functionality, tools, and systems for any domain to seamlessly consume and create data products. This team must also provide the federated governance policies.
Processes: The federated governance policies need to embed within the processes of each domain governance policies such as interoperability, documentation, security, privacy, and compliance.
Technology: You need self-service data infrastructure as a platform that provides the domain teams with the capability to prep, host, and serve their data products. There is not currently a single, stand-alone tool or platform you can use to fully establish a data mesh architecture so you’ll have to employ a mix of solutions.
For example, incorporating a data mesh into your integration platform as a service (iPaaS) would involve creating connectors and integrations that allow data to be consumed and produced by the self-serve data products. This would require a flexible and modular approach to integration, where each data product can be treated as a separate endpoint that can be connected to other endpoints within the iPaaS. The iPaaS would need to provide a way to manage the data products and ensure their quality, as well as the ability to track data lineage and governance. This would require integrating metadata management and data governance tools into the iPaaS.
It’s not recommended that you overhaul your entire architecture at once. Instead, start with a one discrete project. Pick one domain that has an easily definable business value, such as marketing, which uses data to measure response rates. You’ll gain valuable learnings that you can apply with other domains as you roll out your new approach. These learning will include things like providing the appropriate level of self-service capabilities based on the business needs of each domain.
DataOps for Analytics
Modern data integration delivers real-time, analytics-ready and actionable data to any analytics environment, from Qlik to Tableau, Power BI and beyond.
-

Real-Time Data Streaming (CDC)
Extend enterprise data into live streams to enable modern analytics and microservices with a simple, real-time and universal solution. -

Agile Data Warehouse Automation
Quickly design, build, deploy and manage purpose-built cloud data warehouses without manual coding. -

Managed Data Lake Creation
Automate complex ingestion and transformation processes to provide continuously updated and analytics-ready data lakes.