Data Lakehouse
What it is, key features, and benefits. This guide defines and compares data lakehouses, data lakes and data warehouses to help you evaluate which structure is best for your organization.
What is a Data Lakehouse?
A data lakehouse is a data management architecture that combines key capabilities of data lakes and data warehouses. It brings the benefits of a data lake, such as low storage cost and broad data access, and the benefits of a data warehouse, such as data structures and management features.
Data Lakehouse Features and Benefits
The lakehouse structure ensures that data analysts and data scientists can apply the full and most recent data set toward business intelligence, data analytics and machine learning. And having one system to manage simplifies the enterprise data infrastructure and allows analysts and scientists to work more efficiently.
Here we present the key features of data lakehouses and the benefits they bring to your organization.
| FEATURE | BENEFIT |
|---|---|
|
Concurrent read & write transactions Data lakehouses can handle multiple data pipelines. |
Multiple users can concurrently read and write ACID-compliant transactions without compromising data integrity.
|
|
Data warehouse schema architectures Data lakehouses can apply a schema to all data. |
This means lakehouses can standardize large datasets.
|
|
Governance mechanisms Lakehouses can support strong governance and auditing capabilities. |
Having a single control point lets you better control publishing, sharing and user access to data.
|
|
Open & standardized storage formats Lakeshouses use open, standardized storage formats such as AVRO, ORC or Parquet. They additionally support tabular formats too. |
Open formats facilitate broad, flexible and efficient data consumption from BI tools to programming languages such as Python and R. Many also support SQL.
|
|
Separation of storage & processing Like some modern data warehouses, lakehouses decouple storage and compute resources by using separate clusters for storing and processing. |
You can scale to larger datasets and have more concurrent users. Plus, these clusters run on inexpensive hardware, which saves you money.
|
|
Support for diverse data types Data lakehouses give you access to structured, semi-structured and unstructured data types. |
This allows you to store, access, refine and analyze a broad range of data types and applications, such as IoT data, text, images, audio, video, system logs and relational data.
|
|
Support for end-to-end streaming Data lakehouses support data streaming. |
This enables real-time reporting and analysis. Plus, you no longer need separate systems dedicated to serving real-time data apps.
|
|
Single repository for many applications Lakehouses allow you to use business intelligence tools, process machine learning projects, perform data science, and SQL & analytics directly on a single repository of clean, integrated source data. |
This improves operational efficiency and data quality for BI, ML and other workloads since you only have to maintain one data repository.
|
3 Ways to Increase Your Data Lake ROI
Data Lakehouse vs Data Warehouse vs Data Lake
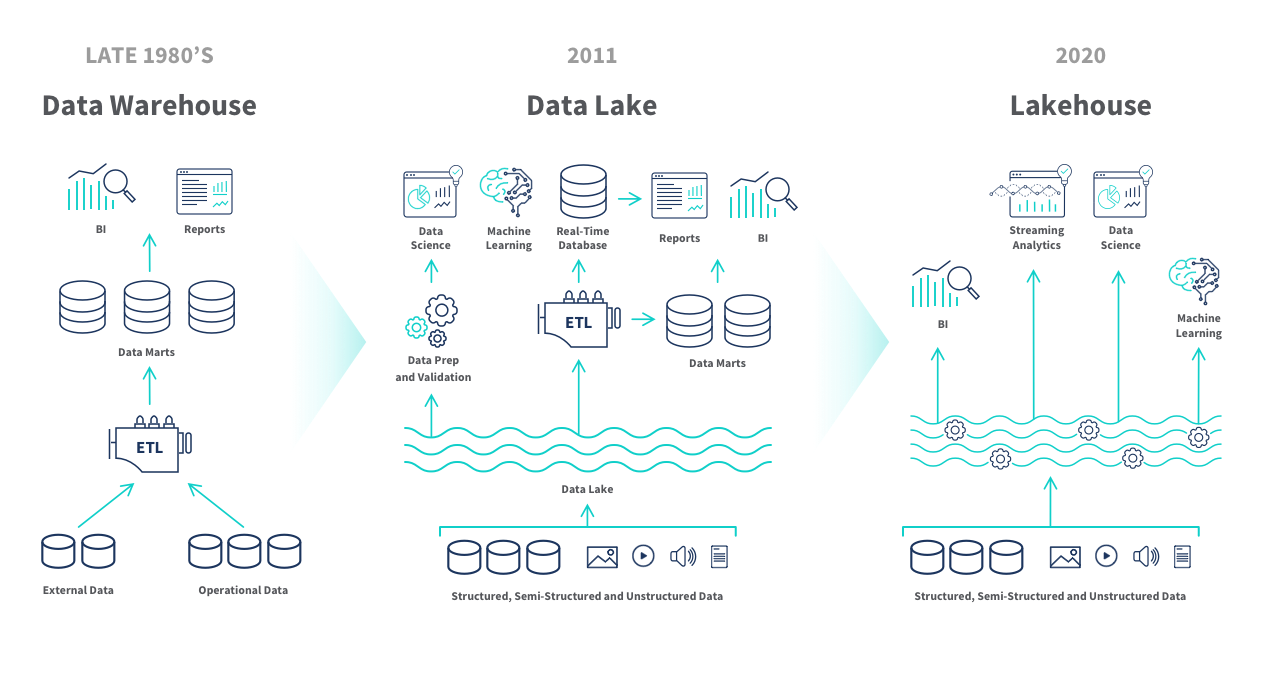
Historically, you’ve had two primary options for a data repository: data lake or data warehouse. To support BI, data science and machine learning, it’s likely that you’ve had to maintain both of these structures simultaneously and link the systems together. This often leads to data duplication, security challenges and additional infrastructure expense. Data lakehouses can overcome these issues.
Data Warehouse
Data warehouses hold highly structured and unified data to support specific business intelligence and analytics needs. The data has been transformed and fit into a defined schema.
Pros:
- Little or no data prep needed. This makes it faster and easier for analysts and business users to access and analyze the data.
- Unified, harmonized data offers a single source of truth, building trust in data insights and decision-making across business lines.
Cons:
- Not appropriate for storing unstructured or semi-structured data.
- Traditional data warehouses can cost more than data lakes, due to additional operational costs.
Resources:
- Learn more about data warehouses
- Learn about cloud data warehouses
Data Lake
Data lakes hold raw, source data in a wide variety of formats to directly support data science and machine learning. Massive volumes of structured and unstructured data like ERP transactions and call logs can be stored cost effectively. Data teams can build data pipelines and schema-on-read transformations to make data stored in a data lake available for BI and analytics tools.
Pros:
- Storage costs and operational costs can be less compared to a data warehouse.
- Data scientists or end-to-end self-service BI tools can gain access to a broader range of data far faster than in a data warehouse because it is kept in a raw state.
- Data can be analyzed in new ways to gain unexpected and previously unavailable insights.
Cons:
- Streaming and appending data can be difficult leading to inconsistency and isolation.
- Data lakes don’t support transactional data.
- Data lakes don’t enforce data quality.
Resources:
- Learn more about data lakes
- Take a deeper look at data lake vs data warehouse
Data Lakehouse
The data lakehouse can be more flexible than the traditional data warehouse or data lake architecture in that it can eliminate data redundancy and improve data quality while offering lower cost storage. ETL pipelines provide the critical link between the unsorted lake layer and the integrated warehouse layer. A growing ecosystem of providers such as Databricks, Google BigQuery, Azure Synapse, Snowflake and Amazon Redshift, offer solutions that allow the data to be cost-effectively stored.
Pros:
- A single data repository requires less time and budget to administer than a multiple-solution system.
- Lower data storage cost.
- Direct access to broader dataset for BI tools.
- Less data movement and redundancy.
- Simplified schema management.
- Simplified data governance due to having a single control point.
- ACID-compliant transaction support
Cons:
- Can be expensive and time-consuming to migrate from traditional data warehouses.
Cloud Data Lake Comparison Guide
Get an unbiased, side-by-side look at all the major cloud data lake vendors, including AWS, Azure, Google, Cloudera, Databricks, and Snowflake.
DataOps for Analytics
Modern data integration delivers real-time, analytics-ready and actionable data to any analytics environment, from Qlik to Tableau, Power BI and beyond.
-

Real-Time Data Streaming (CDC)
Extend enterprise data into live streams to enable modern analytics and microservices with a simple, real-time and universal solution. -

Agile Data Warehouse Automation
Quickly design, build, deploy and manage purpose-built cloud data warehouses without manual coding. -

Managed Data Lake Creation
Automate complex ingestion and transformation processes to provide continuously updated and analytics-ready data lakes.