Data Mining
What it is, why it matters, and key techniques. This guide provides definitions and practical advice to help you understand and practice modern data mining.
What is Data Mining?
Data mining is the process of using statistical analysis and machine learning to discover hidden patterns, correlations, and anomalies within large datasets. This information can aid you in decision-making, predictive modeling, and understanding complex phenomena.
How It Works
Data mining can be seen as a subset of data analytics that specifically focuses on extracting hidden patterns and knowledge from data. Historically, a data scientist was required to build, refine, and deploy models. However, with the rise of AutoML tools, data analysts can now perform these tasks if the model is not too complex.
The data mining process may vary depending on your specific project and the techniques employed, but it typically involves the 10 key steps described below.

1. Define Problem. Clearly define the objectives and goals of your data mining project. Determine what you want to achieve and how mining data can help in solving the problem or answering specific questions.
2. Collect Data. Gather relevant data from various sources, including databases, files, APIs, or online platforms. Ensure that the collected data is accurate, complete, and representative of the problem domain. Modern analytics and BI tools often have data integration capabilities. Otherwise, you’ll need someone with expertise in data management to clean, prepare, and integrate the data.
3. Prep Data. Clean and preprocess your collected data to ensure its quality and suitability for analysis. This step involves tasks such as removing duplicate or irrelevant records, handling missing values, correcting inconsistencies, and transforming the data into a suitable format.
4. Explore Data. Explore and understand your data through descriptive statistics, visualization techniques, and exploratory data analysis. This step helps in identifying patterns, trends, and outliers in the dataset and gaining insights into the underlying data characteristics.
5. Select predictors. This step, also called feature selection/engineering, involves identifying the relevant features (variables) in the dataset that are most informative for the task. This may involve eliminating irrelevant or redundant features and creating new features that better represent the problem domain.
6. Select Model. Choose an appropriate model or algorithm based on the nature of the problem, the available data, and the desired outcome. Common techniques include decision trees, regression, clustering, classification, association rule mining, and neural networks. If you need to understand the relationship between the input features and the output prediction (explainable AI), you may want a simpler model like linear regression. If you need a highly accurate prediction and explainability is less important, a more complex model such as a deep neural network may be better.
7. Train Model. Train your selected model using the prepared dataset. This involves feeding the model with the input data and adjusting its parameters or weights to learn from the patterns and relationships present in the data.
8. Evaluate Model. Assess the performance and effectiveness of your trained model using a validation set or cross-validation. This step helps in determining the model's accuracy, predictive power, or clustering quality and whether it meets the desired objectives. You may need to adjust the hyperparameters to prevent overfitting and improve the performance of your model.
9. Deploy Model. Deploy your trained model into a real-world environment where it can be used to make predictions, classify new data instances, or generate insights. This may involve integrating the model into existing systems or creating a user-friendly interface for interacting with the model.
10. Monitor & Maintain Model. Continuously monitor your model's performance and ensure its accuracy and relevance over time. Update the model as new data becomes available, and refine the data mining process based on feedback and changing requirements.
Flexibility and iterative approaches are often required to refine and improve the results throughout the process.
Learn How to Get Started
Download the AutoML guide with 5 factors for machine learning success
Data Mining Techniques
There are a wide array of data mining techniques used in data science and data analytics. Your choice of technique depends on the nature of your problem, the available data, and the desired outcomes. Predictive modeling is a fundamental component of mining data and is widely used to make predictions or forecasts based on historical data patterns. You may also employ a combination of techniques to gain comprehensive insights from the data. Top-10 data mining techniques:
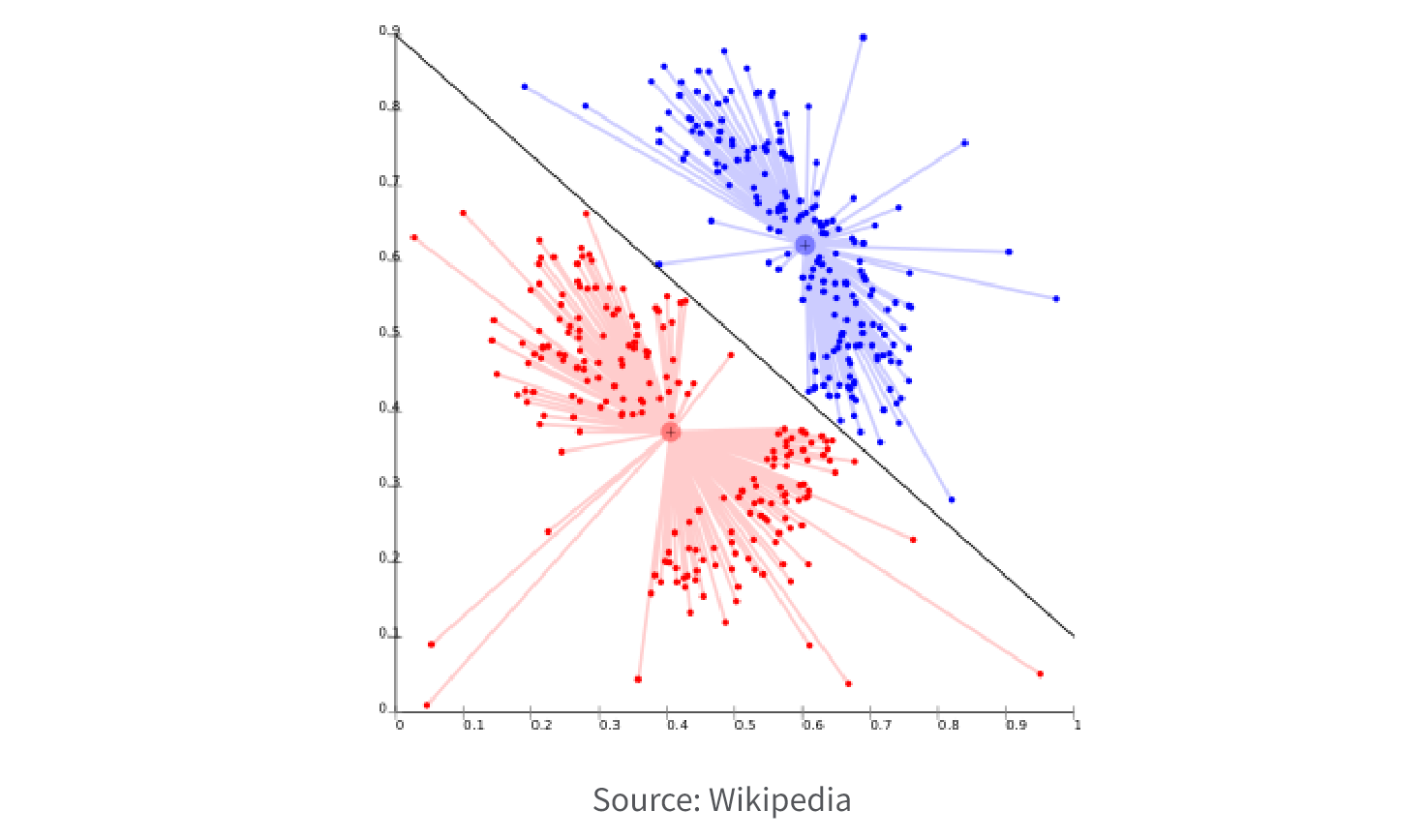
1. Classification
Classification is a technique used to categorize data into predefined classes or categories based on the features or attributes of the data instances. It involves training a model on labeled data and using it to predict the class labels of new, unseen data instances.
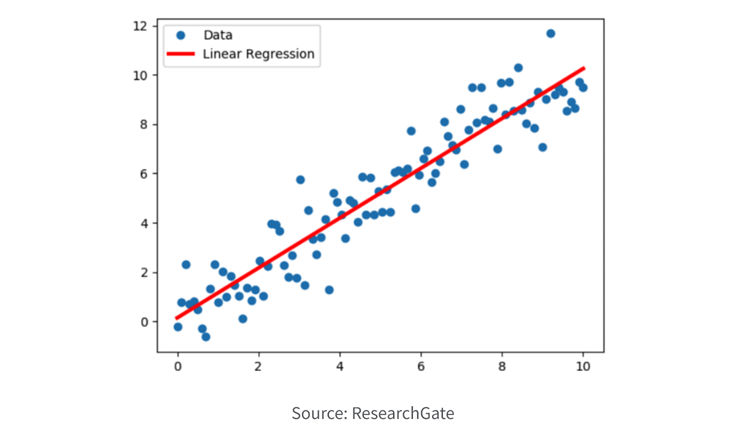
2. Regression
Regression is employed to predict numeric or continuous values based on the relationship between input variables and a target variable. It aims to find a mathematical function or model that best fits the data to make accurate predictions.
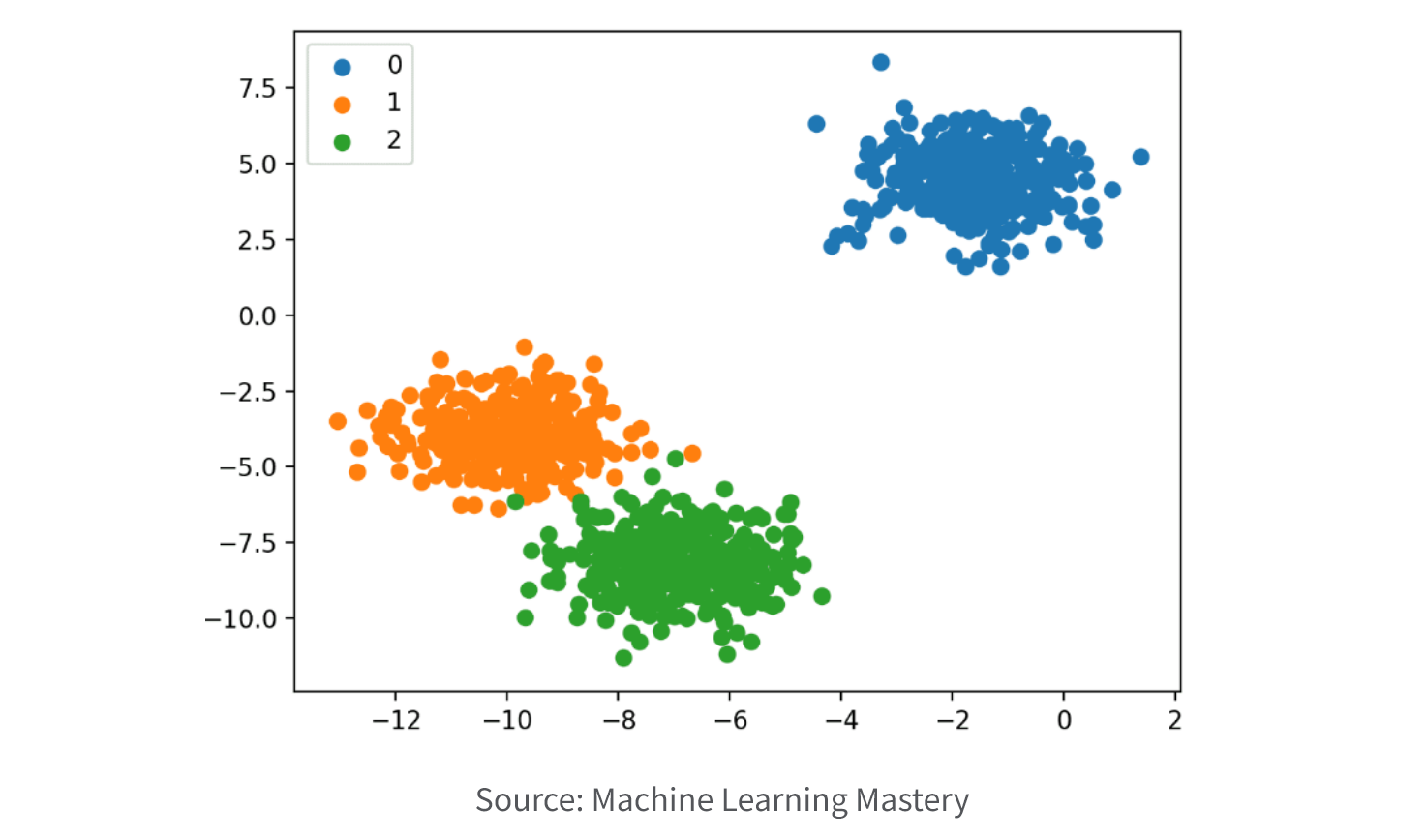
3. Clustering
Clustering is a technique used to group similar data instances together based on their intrinsic characteristics or similarities. It aims to discover natural patterns or structures in the data without any predefined classes or labels.
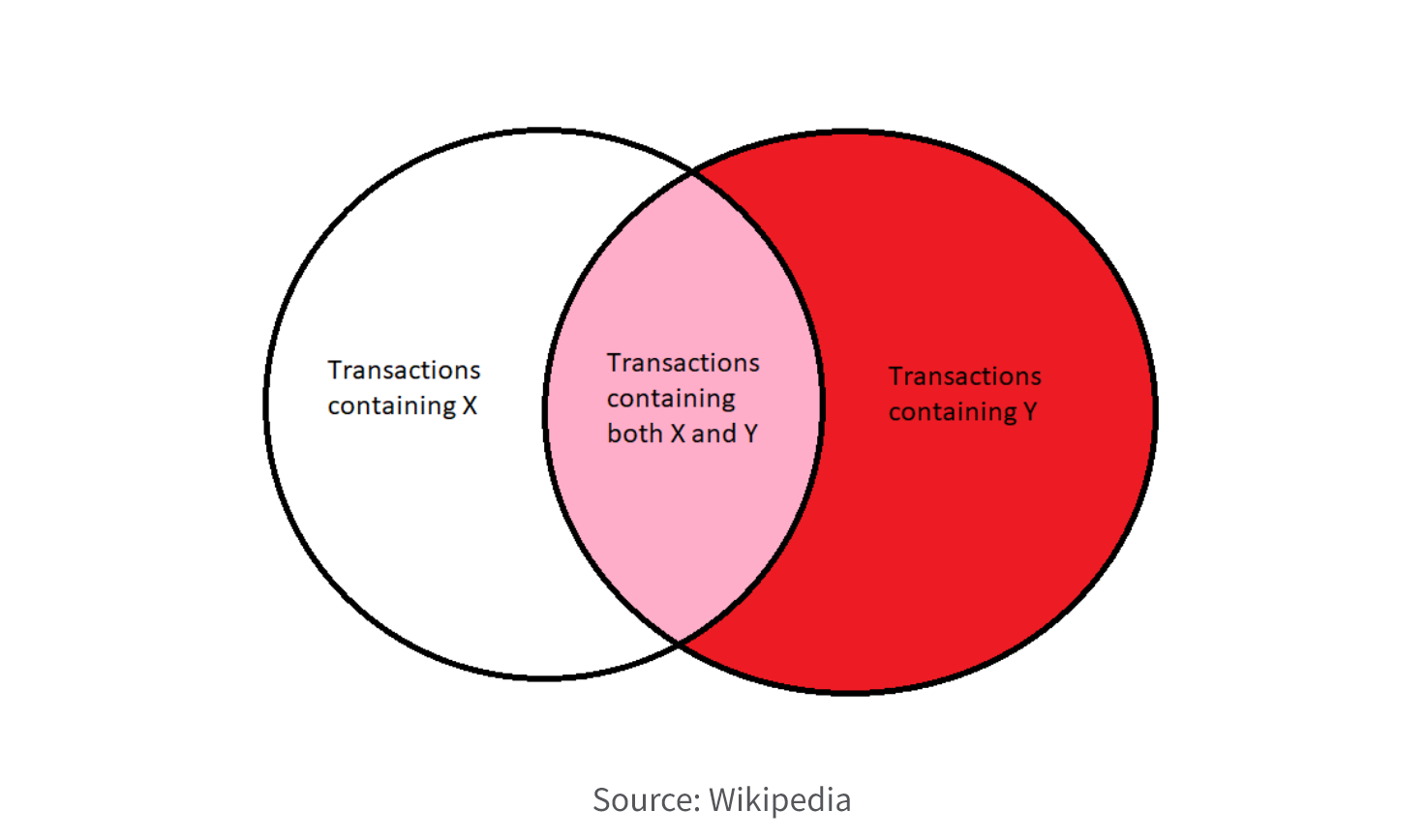
4. Association Rule
Association rule mining focuses on discovering interesting relationships or patterns among a set of items in transactional or market basket data. It helps identify frequently co-occurring items and generates rules such as "if X, then Y" to reveal associations between items. This simple Venn diagram shows the associations between itemsets X and Y of a dataset.
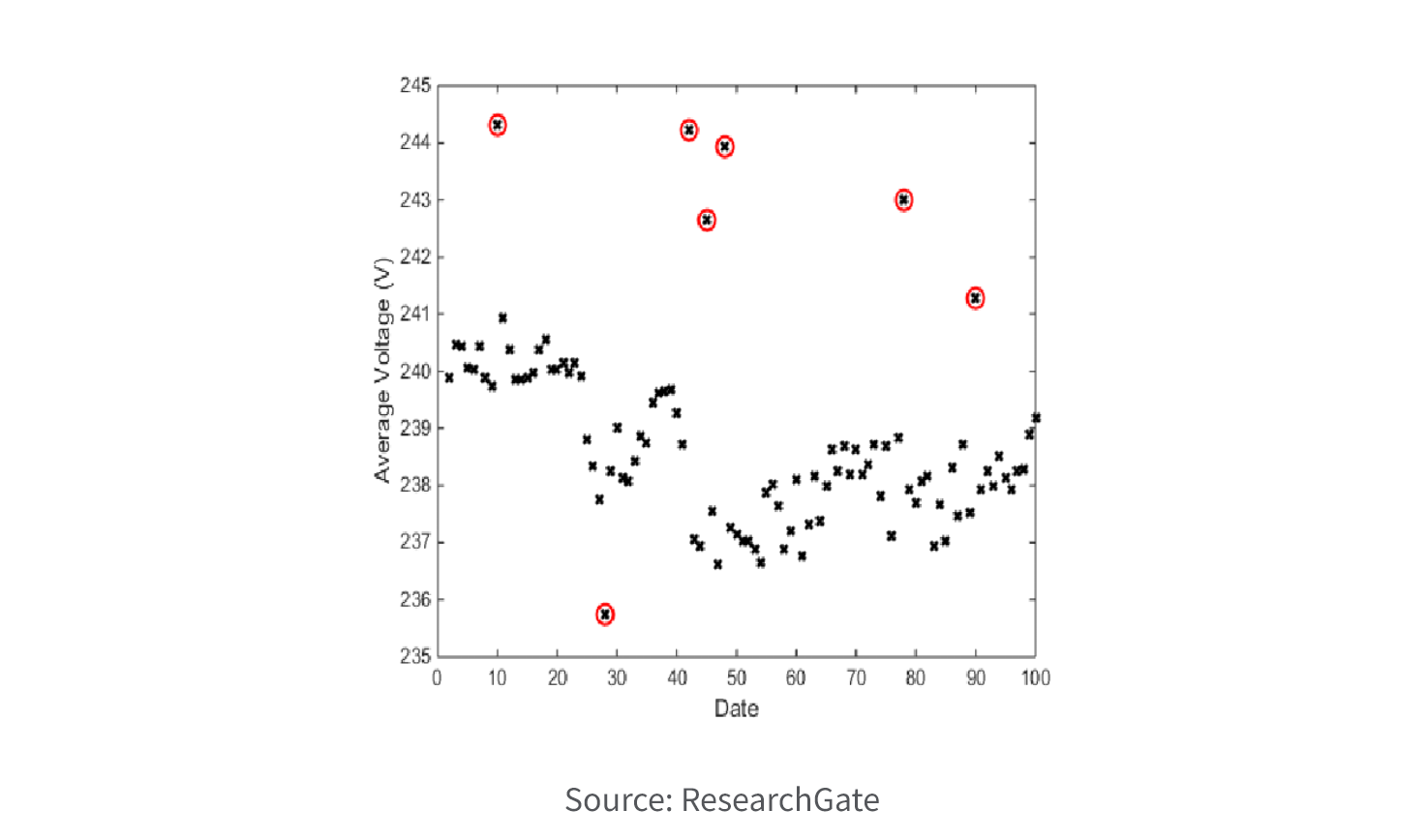
5. Anomaly Detection
Anomaly detection, sometimes called outlier analysis, aims to identify rare or unusual data instances that deviate significantly from the expected patterns. It is useful in detecting fraudulent transactions, network intrusions, manufacturing defects, or any other abnormal behavior.
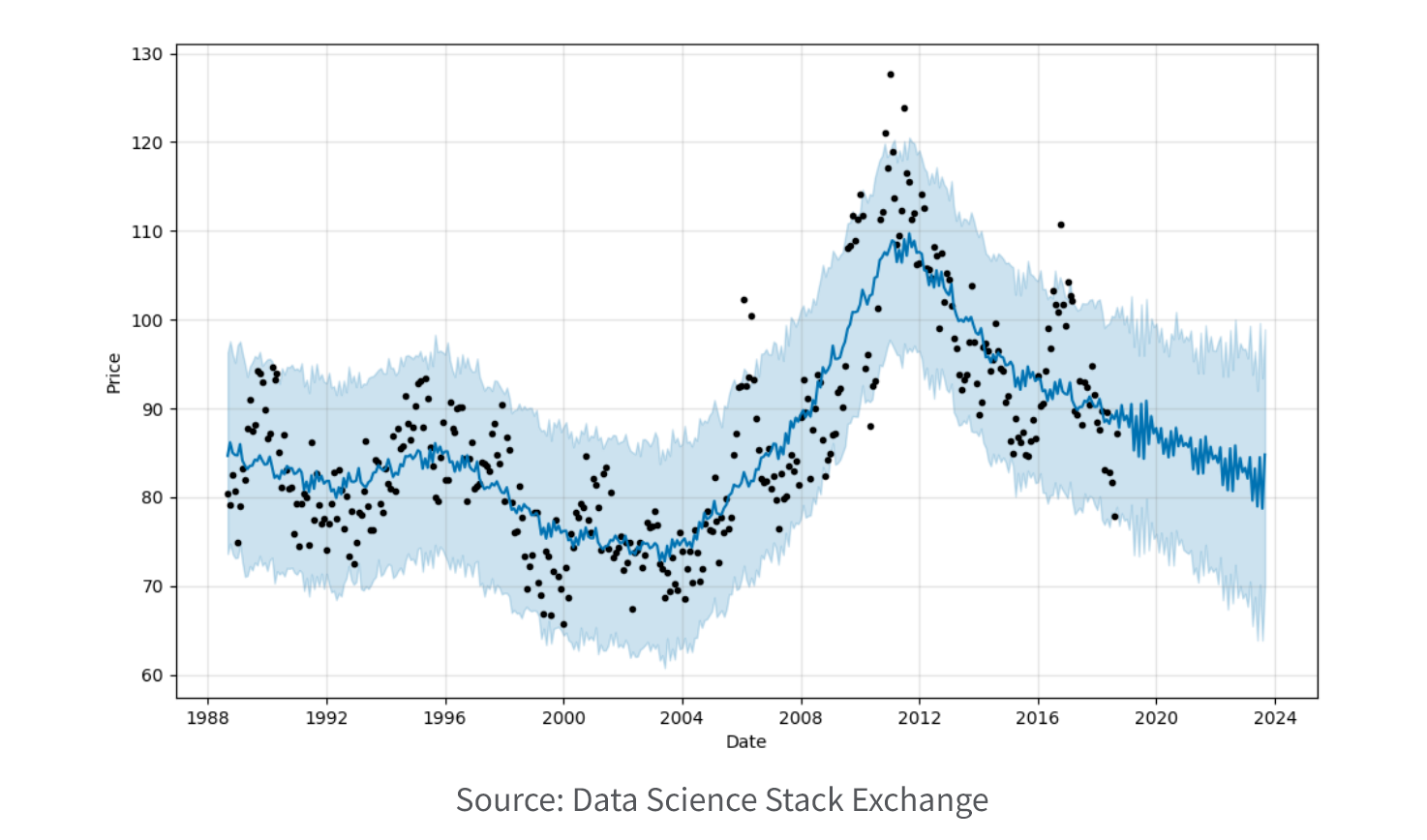
6. Time Series Analysis
Time series analysis focuses on analyzing and predicting data points collected over time. It involves techniques such as forecasting, trend analysis, seasonality detection, and anomaly detection in time-dependent datasets.
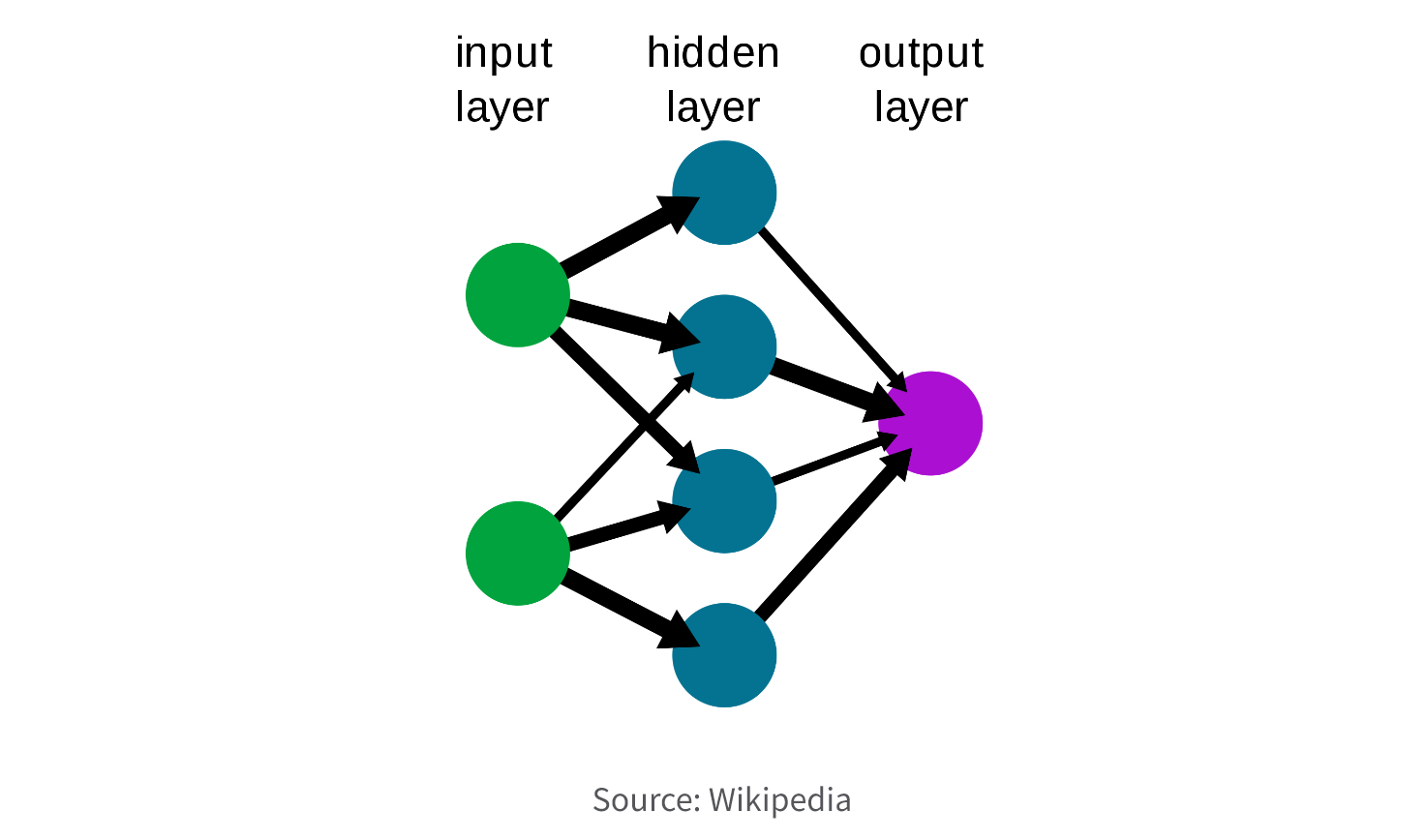
7. Neural Networks
Neural networks are a type of machine learning or AI model inspired by the human brain's structure and function. They are composed of interconnected nodes (neurons) and layers that can learn from data to recognize patterns, perform classification, regression, or other tasks.
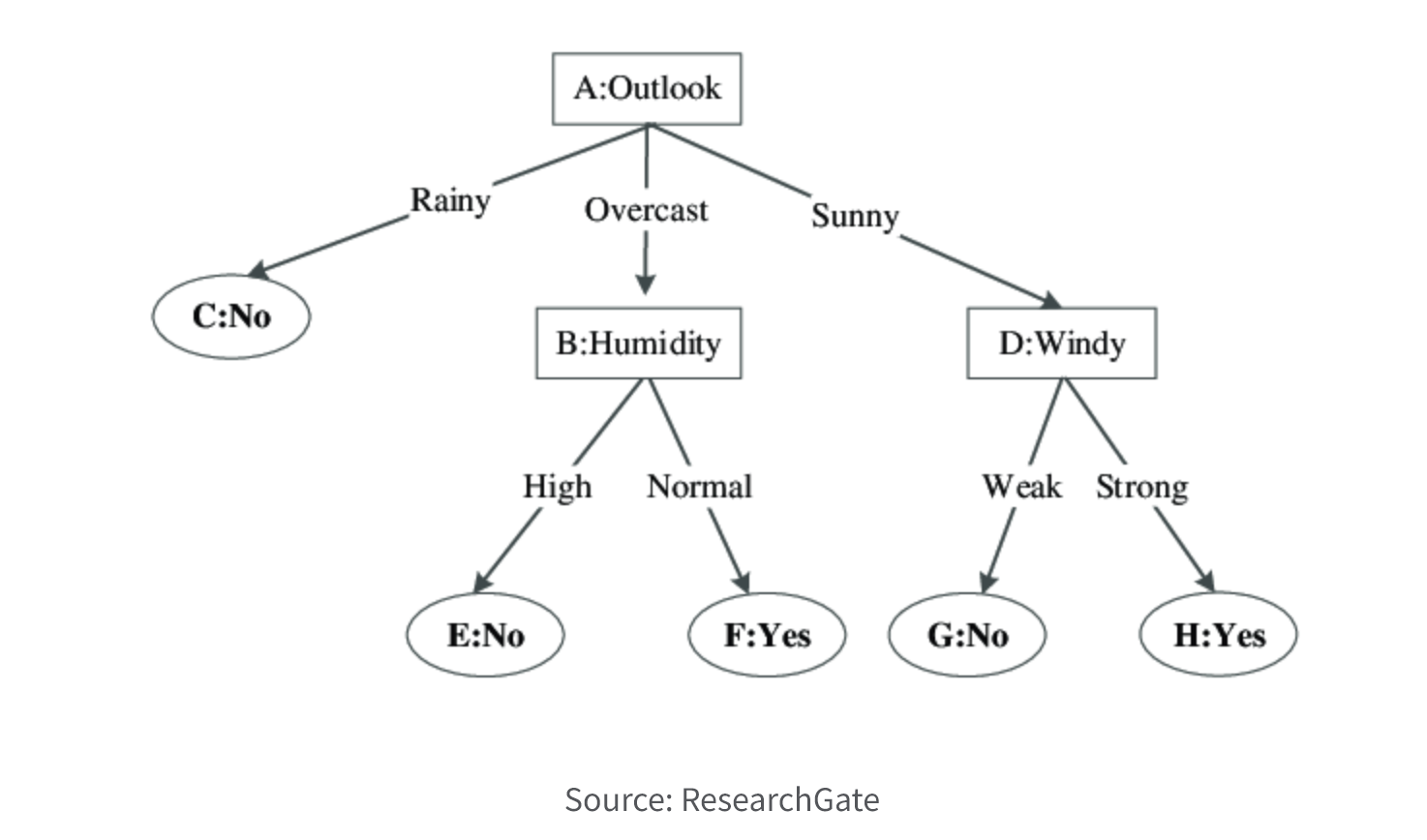
8. Decision Trees
Decision trees are graphical models that use a tree-like structure to represent decisions and their possible consequences. They recursively split the data based on different attribute values to form a hierarchical decision-making process.
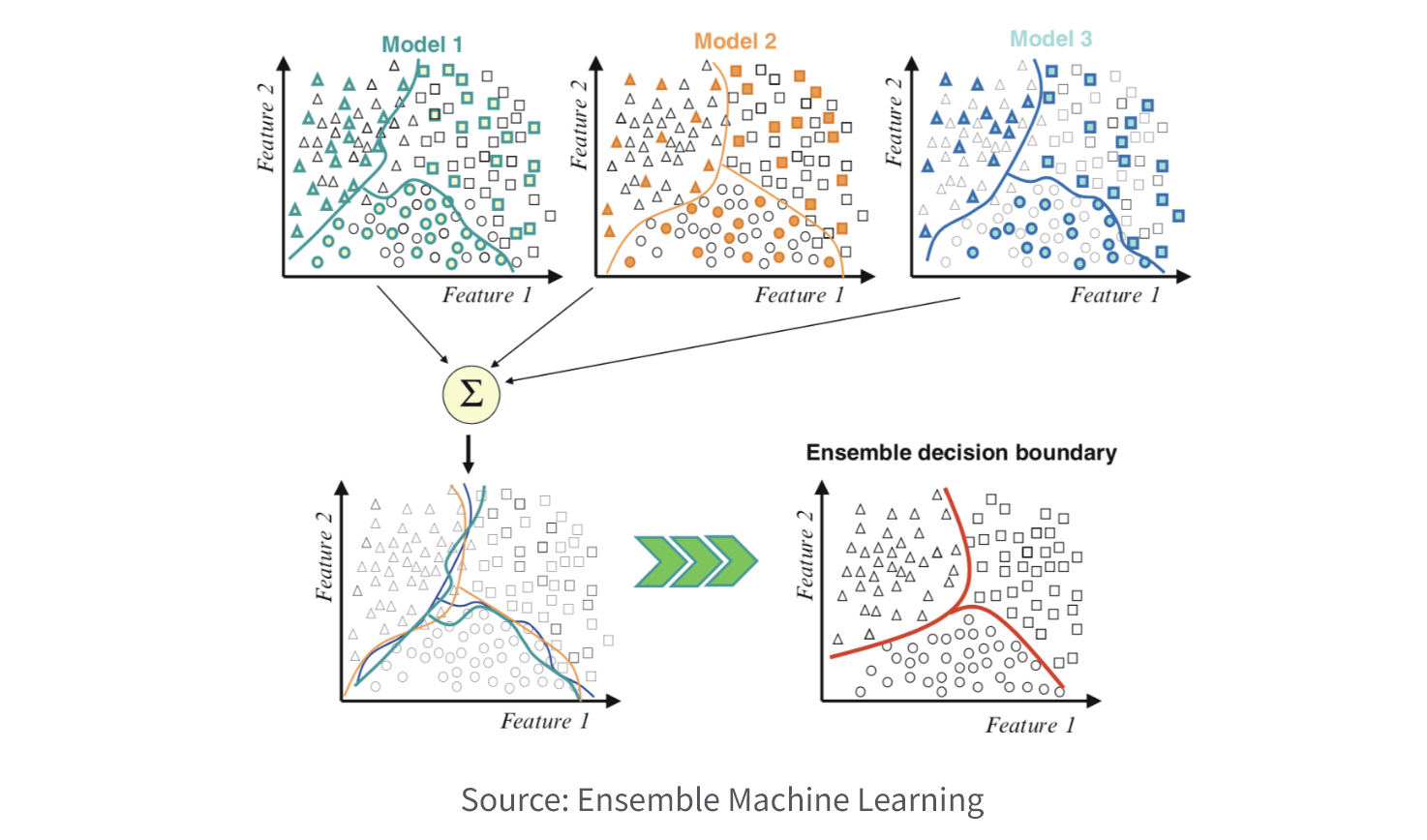
9. Ensemble Methods
Ensemble methods combine multiple models to improve prediction accuracy and generalization. Techniques like Random Forests and Gradient Boosting utilize a combination of weak learners to create a stronger, more accurate model.
10. Text Mining
Text mining techniques are applied to extract valuable insights and knowledge from unstructured text data. Text mining includes tasks such as text categorization, sentiment analysis, topic modeling, and information extraction, enabling your organization to derive meaningful insights from large volumes of textual data, such as customer reviews, social media posts, emails, and articles.
10 Ways to Take Your Visualizations to the Next Level
Data Mining Examples
Data mining has diverse applications in different industries, providing value in improving decision-making, detecting patterns, optimizing processes, and enhancing customer experiences. Here are 8 top data mining examples.
-

Retailers often use data mining techniques to analyze customer purchase history and identify patterns or associations. For example, market basket analysis can reveal that customers who buy diapers are also likely to purchase baby food, leading to cross-selling opportunities.
-

It plays a crucial role in healthcare by analyzing electronic health records, medical imaging data, and clinical trials. It helps in predicting disease outcomes, identifying risk factors, improving treatment plans, and detecting potential adverse drug reactions.
-

Financial services institutions mine data to detect fraudulent transactions by analyzing patterns, anomalies, and behaviors. It helps in financial analysis, identifying suspicious activities, preventing financial fraud, and ensuring the security of transactions.
-

Marketing and CRM (Customer Relationship Management) professionals use it to assist in customer segmentation, targeting, and personalized marketing campaigns. By analyzing customer demographics, behaviors, and preferences, you can tailor your marketing strategies to specific customer segments, increasing the effectiveness of their campaigns.
-

Mining techniques are employed to analyze social media data, such as tweets, posts, and comments, to gain insights into customer sentiment, product feedback, and emerging trends. Sentiment analysis helps organizations understand public opinion and brand perception.
-

It’s utilized in manufacturing and supply chain management to optimize manufacturing processes, identify bottlenecks, and improve supply chain efficiency. It helps in demand forecasting, inventory management, and quality control, leading to cost reduction and improved productivity.
-

Mining data is valuable in the telecommunications industry for analyzing call detail records, customer usage patterns, and network data. It helps in identifying network performance issues, optimizing network resources, and predicting customer churn.
-

It’s used in various sectors, including insurance and credit card companies, to detect fraudulent activities. By analyzing transactional patterns and customer behavior, mining algorithms can identify suspicious transactions and flag potential fraud cases.
Benefits
In the modern era of data-driven operations, your organization faces the challenge of managing vast and dynamic datasets originating from multiple sources. Augmented analytics, including data mining, predictive modeling, predictive analytics, and prescriptive analytics, helps you harness big data effectively.
Data mining has a broad range of benefits such as helping you uncover patterns, improve decision-making, personalize experiences, detect fraud, optimize processes, and drive innovation.
- Uncover Hidden Patterns: Mining data helps discover valuable patterns, correlations, and relationships within large datasets that may not be readily apparent. These hidden patterns can provide insights into customer behavior, market trends, and business processes.
- Improve Decision-Making: By analyzing historical data and identifying patterns, it enables organizations to make informed and data-driven decisions. It helps identify factors that contribute to success or failure, optimize processes, and predict future outcomes.
- Segment Customers and Personalize Experiences: Mining data allows organizations to segment their customer base and identify distinct groups with similar characteristics. This segmentation helps in creating targeted marketing campaigns, personalized recommendations, and tailored customer experiences.
- Conduct Market Basket Analysis and Cross-Selling: By analyzing transactional data, data mining enables organizations to understand customer purchasing patterns and perform market basket analysis. This analysis helps in cross-selling and identifying product associations for targeted marketing strategies.
- Detect Fraud and Assess Risks: Mining techniques can be employed to detect fraudulent activities by identifying anomalous patterns or behaviors. It helps in fraud prevention, risk assessment, and enhancing security measures in areas such as finance, insurance, and cybersecurity.
- Forecast with Predictive Analytics: Mining data enables organizations to build predictive models that forecast future trends, behaviors, or events. This helps in proactive planning, demand forecasting, inventory management, and optimizing business strategies.
- Optimize Processes: Mining data can uncover inefficiencies or bottlenecks in business processes by analyzing large datasets. It helps in identifying areas for improvement, streamlining operations, reducing costs, and enhancing overall efficiency.
- Enhance Customer Insights: It allows organizations to gain a deeper understanding of their customers by analyzing various data sources. It helps identify customer preferences, behavior patterns, and sentiment analysis, which can be leveraged to enhance customer satisfaction and loyalty.
- Conduct Scientific Research and Exploration: Mining data is valuable in scientific research for exploring and analyzing complex datasets. It helps identify correlations, uncover new knowledge, and support decision-making in areas such as healthcare, genomics, astronomy, and social sciences.
Data Mining Tools
The best data mining tools offer a range of capabilities that enable you to extract valuable insights and patterns from large datasets. Modern visualization software and BI tools simplify the integration of diverse data sources and facilitate advanced analytical techniques such as regression analysis, univariate analysis, bivariate analysis, multivariate analysis, and principal components analysis.
These tools enable real-time data monitoring, collaborative capabilities, and the sharing of insights through interactive data dashboards. Moreover, top-notch tools offer AutoML integration, streamlining the process of creating personalized machine learning models.
Key Capabilities of Data Mining Tools:
Data preprocessing involves cleaning, transforming, and integrating data from different sources. This includes handling missing values, removing outliers, and normalizing data to ensure data quality and consistency.
Data exploration and visualization techniques help you understand the underlying patterns and relationships in the data. Your data mining tool should provide interactive charts, graphs, and summary statistics to help you gain insights and identify important variables or trends.
Predictive modeling, using a variety of algorithms, should also be supported. These models utilize historical data to make predictions or classifications on new, unseen data instances. You can evaluate and compare different models to select the most accurate and reliable one.
Clustering and segmentation capabilities enable you to identify natural groupings or clusters within the data. Clustering algorithms help in segmenting data based on similarity or proximity, allowing for targeted marketing, customer segmentation, and personalized recommendations.
Association rule mining techniques to identify frequent itemsets and discover relationships between items in transactional or market basket data. This helps in uncovering patterns like "if X, then Y" and supports tasks such as cross-selling, recommendation systems, and market basket analysis.
Text mining and natural language processing (NLP) allows you to analyze and extract insights from unstructured textual data. This includes tasks such as sentiment analysis, text categorization, topic modeling, and entity extraction.
Anomaly detection helps identify unusual or abnormal patterns in your data. This capability is useful in detecting fraudulent activities, network intrusions, manufacturing defects, or any other outliers that deviate from expected behavior.
Your tool should make it easy to integrate with other data analytics tools and platforms, including databases, statistical analysis software, programming languages, and visualization tools. This allows you to leverage a wider range of functionalities.
The best data mining tools provide mechanisms to evaluate the performance of predictive models using various metrics such as accuracy, precision, recall, and F1 score. Once a model is deemed satisfactory, these tools support the deployment of models for real-time predictions or integration into other applications.
Scalability and performance is critical since your tool needs to handle large volumes of data efficiently. It should be able to process and analyze massive datasets and handle the computational demands of complex data mining tasks.
Modern Analytics Demo Videos
See how to explore information and quickly gain insights.
- Combine data from all your sources
- Dig into KPI visualizations and dashboards
- Get AI-generated insights
Frequently Asked Questions
What do you mean by data mining?
Here is a data mining definition: Data mining is the process of extracting meaningful patterns, anomalies, and insights from large volumes of data. Techniques such as statistical analysis and machine learning can help you discover hidden patterns, correlations, and relationships within datasets. This information can aid you in decision-making, predictive modeling, and understanding complex phenomena.
What are the key types of data mining?
The key types of data mining are as follows: classification, regression, clustering, association rule mining, anomaly detection, time series analysis, neural networks, decision trees, ensemble methods, and text mining.
Is it hard to learn data mining?
Learning data mining can vary in difficulty depending on factors like prior knowledge, educational background, and experience with data analysis and programming. Proficiency in programming languages such as Python or R, as well as understanding mathematical and statistical concepts, is often required. Acquiring these technical skills may take time and effort, but having domain knowledge in the relevant field can be beneficial. Further, new AutoML tools streamline the process of creating machine learning models.
How does data mining work?
Data mining works by applying automated techniques and algorithms to analyze the data, identify hidden relationships, and discover meaningful patterns that may not be readily apparent. Initially, the data is collected from various sources and undergoes preprocessing, including cleaning and transforming, to ensure its quality and compatibility. Next, data mining algorithms are applied to the prepared data to uncover patterns, associations, correlations, and trends. These patterns and insights can be used for various purposes, such as prediction, classification, clustering, or anomaly detection. The results obtained from data mining enable you to make informed decisions, gain a deeper understanding of your data, and uncover valuable knowledge that can drive business success.
What are the advantages and disadvantages of data mining?
Data mining offers several advantages and disadvantages. On the positive side, it allows organizations to uncover hidden patterns and valuable insights from large volumes of data, enabling better decision-making, improved business strategies, and enhanced customer satisfaction. It can identify trends, predict future outcomes, and detect anomalies or fraud. It also helps in personalized marketing, targeted advertising, and customer segmentation. However, there are challenges and drawbacks to consider. Data mining requires significant computational resources, expertise in algorithms, and data preprocessing. Privacy concerns and ethical considerations arise when dealing with sensitive or personal data. There may be biases in the data that can affect the accuracy and fairness of the results. Additionally, results may lead to unintended consequences if misinterpreted or misapplied.