Database Replication
What it is, why you need it, and best practices. This guide provides definitions and practical advice to help you understand and manage database replication.
What Is Database Replication?
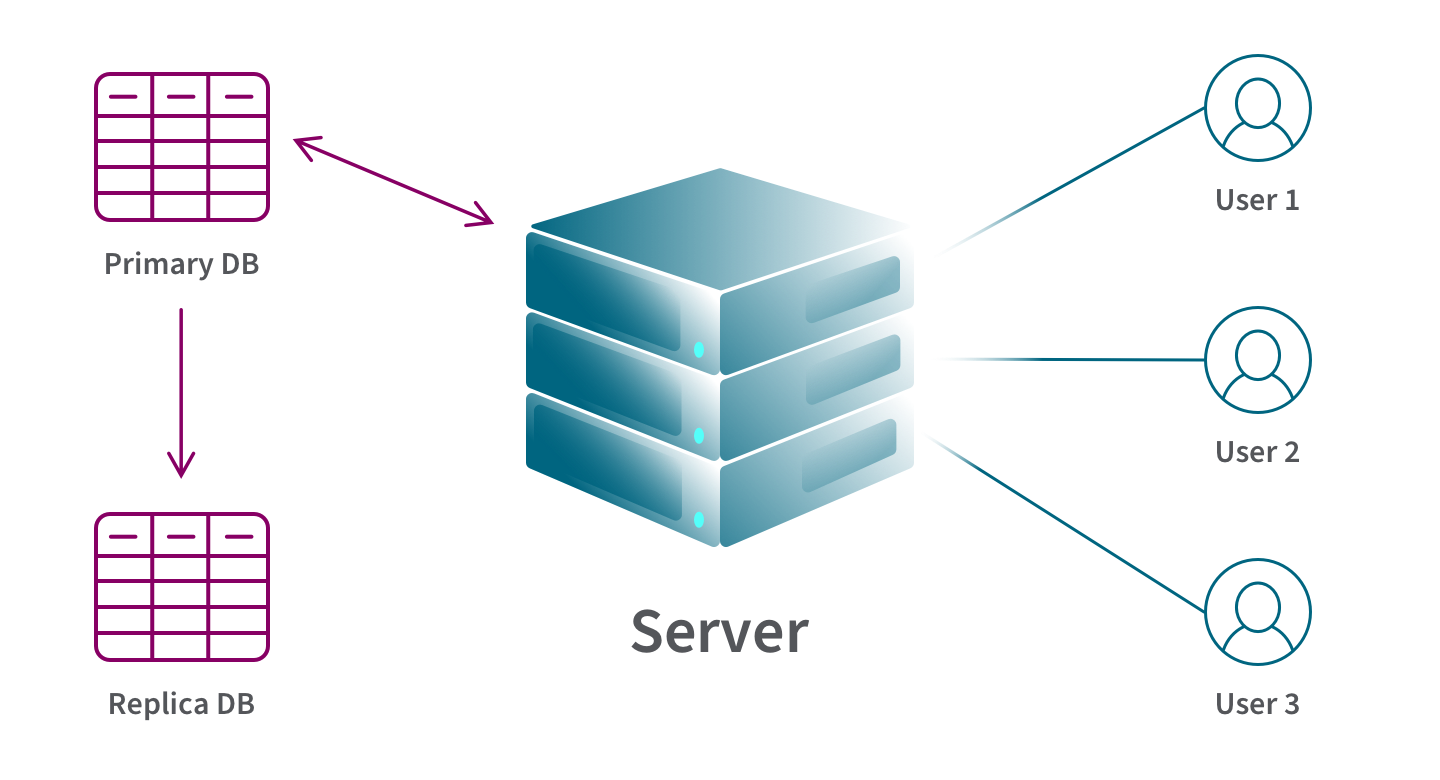
Database replication refers to the process of copying data from a primary database to one or more replica databases in order to improve data accessibility and system fault-tolerance and reliability. Database replication is typically an ongoing process which occurs in real time as data is created, updated, or deleted in the primary database but it can also occur as one-time or scheduled batch projects.
Benefits of Replicating Data
Your organization may have a wide variety of heterogeneous databases, data warehouses, and big data platforms. And, your organization might be spread out geographically, have multiple departments wanting access to the same dataset, or you may have complex data issues like storing data across on premises, cloud, and hybrid multicloud.
Data replication moves your data efficiently and securely across your data integration system. This helps you to improve the performance and availability of your databases and the applications that depend on them, to incorporate new technologies into your IT infrastructure, and to enable data analytics on non-production systems.

Below are the key benefits of replicating databases for your organization.
Business benefits:
- Trusted, holistic picture for analytics. Database replication will help you bring together data from different sources and repositories such as a data lake or data warehouse. This will give you a single source of truth, give you a holistic picture of your business, and lets you explore and analyze trusted, governed data. Ultimately, this helps you uncover actionable insights that improve your business.
- Faster insights. Less processing burden for each server means higher performance. This allows all users faster access to the data they need without impacting other teams who also use the same data.
IT/DataOps benefits:
- Higher data availability. Your overall system will still be able to perform adequately even if one of your replicated databases becomes unavailable because you’ll have a copy of the database.
- Reduced server load. A replicated, distributed database requires less processing for each server. This means higher performance for queries.
- More reliable data. As part of the replication process, data in target systems is processed and updated to match that of the source system which helps ensure data integrity.
- Less data movement. Having a distributed database allows for versions of the data to be closer to the point of transaction or data entry.
- Better protection. Achieve redundancy to safeguard the read performance and availability of mission-critical databases and ensure business continuity.
- Lower latency. Having copies of your data in multiple locations means more localized data access, which can improve your network performance. This is especially helpful to employees in satellite offices.
- Better application performance. Improve the scalability and availability of database-dependent applications. This includes enabling data analytics and BI tools on non-production systems.
Challenges for Database Replication
As with most data integration initiatives, your main challenges here involve managing your finite resources of bandwidth, budget, and time. Synchronizing data across your system requires processes which can add traffic to your network, require higher storage and processing expense, and demand ongoing effort to implement and manage.
Beyond those standard resource constraints, your challenges in replicating databases will typically relate to a poorly defined or managed data governance framework.
- Inconsistent data. Some of your data may not correctly sync with the rest of your distributed system when you’re copying data between multiple sites at different intervals.
- Lost data. Some of your data may be lost if database objects are incorrectly configured within the source database or if the primary key you use to verify data integrity in the replica is incorrect.
Also, handling real-time change streams is quite complex and we address this in the CDC section below.
Streaming Change Data Capture
Learn how to modernize your data and analytics environment with scalable, efficient and real-time data replication that does not impact production systems.
3 Types of Database Replication
At the highest level, you can distinguish between one-time projects or an ongoing process. Typically, replicating databases is ongoing and data must be copied frequently enough such that changes in one database are updated across the system.
The three most common techniques are full, incremental, and log-based replication. Each scheme has its own advantages and disadvantages but each ultimately involves balancing the competing needs of data consistency and system performance. The right choice for you will primarily depend on your purpose for the replicated data, the amount of data, and how your data is stored.
1) Full table replication copies all existing, new, and updated data from the primary database to the target, or even to every site in your distributed system.
- Advantages of this technique are higher data availability (because you’ll have a copy of the database even if one of your replicated sites goes down), and faster queries (because they can be performed more locally). Full table is also appropriate if there’s not a suitable column for key-based replication in your primary database, and/or if data records are frequently hard deleted from your primary database.
- Disadvantages of full replication include larger network loads and the need for more processing power which means higher cost. Also, concurrency is harder to achieve and you’ll have a slower update process since single updates are performed at all sites in your distributed system.
2) Key-based incremental replication identifies updated and new data using a replication key column in the primary database and only updates data in the replica databases which has changed since the last update. This key is typically a timestamp, datestamp, or an integer.
- Advantages of key-based replication include increased efficiency because during each update, fewer data rows are copied.
- Disadvantages include the fact that the key value is deleted when the record is deleted in the primary database. This means that key-based replication is not able to detect and replicate data which is hard-deleted in the source.
3) Log-based incremental replication copies data based on the database binary log file, which provides information on changes to the primary database such as inserts, updates, and deletes. Most database vendors support this technique (MySQL, PostgreSQL, Oracle and MongoDB) and, assuming that your primary database structure is relatively static, it’s the most efficient of these three types.
Change Data Capture (CDC) in Database Replication
As stated above, replicating databases in a low-impact way while trying to reliably handle real-time change streams is quite complex. Below are the four main options to process captured data changes:
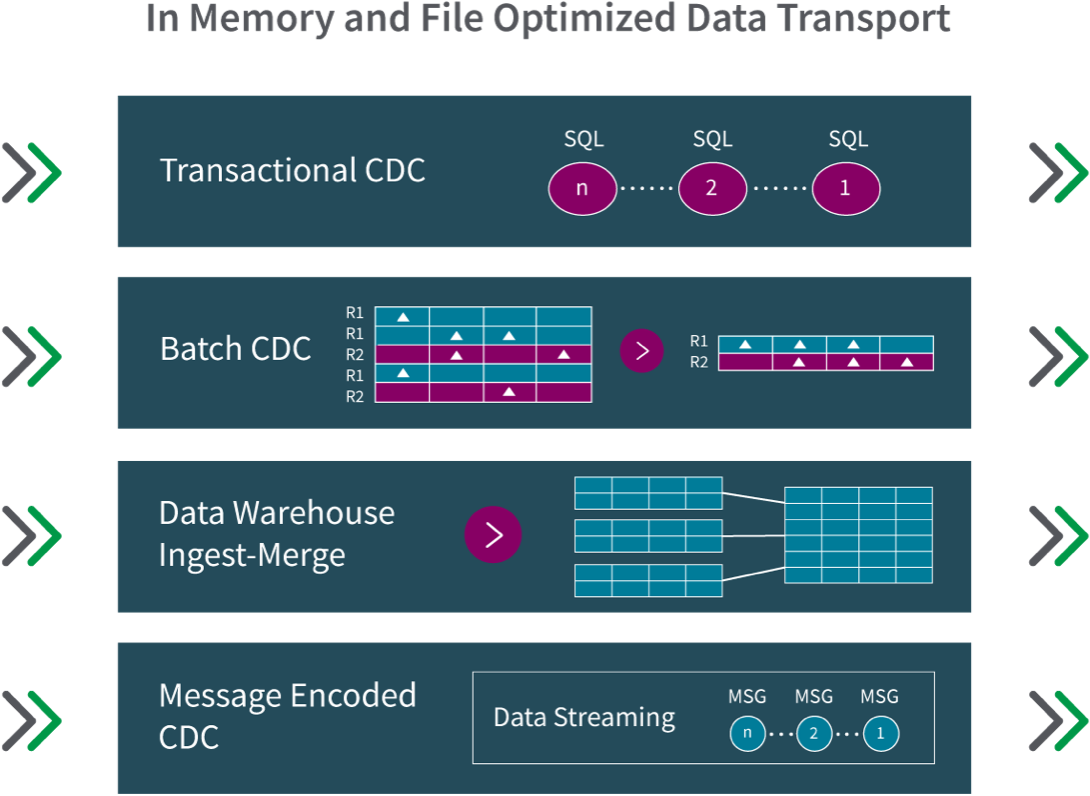
- Transactional CDC applies transactions in the order they were committed to the primary database. This ensures the lowest latency and strict referential integrity.
- Batch-Optimized CDC groups transactions into batches. This optimizes ingestion and merging into data warehouses and many targets on-prem or in the cloud.
- Data Warehouse Ingest-Merge allows for loading with native performance-optimized APIs for Snowflake, Azure Synapse and other EDWs that use massively parallel processing.
- Message-Encoded CDC (also known as Message-Oriented Data Streaming) lets you capture and stream data change records into message broker systems like Apache Kafka.
Database Backup vs Replication
Database replication and database backup (also known as mirroring) are often confused but they are not the same process. Mirroring is a form of data replication whereby you maintain a full database backup as a safety precaution in the event of failure in your primary database. As described above, replication involves database objects and the main goal is typically operational efficiency and higher data availability.
Database Replication Software
You can choose to rely on database replication software provided by your database vendor or you can select a third-party database replication tool. The main advantages of top third-party tools are flexibility and efficiencies. These tools are database-agnostic which means you can use them to copy data across multiple types of databases in your ecosystem.
Learn more:
DataOps for Analytics
Modern data integration delivers real-time, analytics-ready and actionable data to any analytics environment, from Qlik to Tableau, Power BI and beyond.
-

Real-Time Data Streaming (CDC)
Extend enterprise data into live streams to enable modern analytics and microservices with a simple, real-time and universal solution. -

Agile Data Warehouse Automation
Quickly design, build, deploy and manage purpose-built cloud data warehouses without manual coding. -

Managed Data Lake Creation
Automate complex ingestion and transformation processes to provide continuously updated and analytics-ready data lakes.