Data Aggregation
What it is, why you need it, and how it works. This guide provides definitions and practical advice to help you understand and perform data aggregation.
Data Aggregation Guide
What is Data Aggregation?
Data aggregation is the process of combining datasets from diverse sources into a single format and summarizing it to support analysis and decision-making. This makes it easier for you to access and perform statistical analysis on large amounts of data to gain a holistic view of your business and make better informed decisions.
Key Benefits
Aggregating data is an important step in transforming raw data into actionable information. The insights you gain can lead to improved performance, greater efficiency, and increased competitiveness. Here are the key benefits:
Improved Decision-Making: Condensed data provides a holistic view of performance metrics and key indicators, helping you make informed decisions based on summarized, actionable insights. It also becomes easier for you to identify overarching trends, outliers, and patterns in visualizations that may not be apparent when working with raw or siloed data.
Reduced Storage and Better Performance: By consolidating data, aggregation minimizes storage needs and reduces the computational resources required for analysis, leading to more efficient operations. This allows for faster querying and reporting, enhancing the speed at which insights can be obtained and acted upon.
Preserved Privacy and Security: Aggregation can help protect sensitive information by summarizing data without revealing individual-level details, thus mitigating privacy risks.
Smoother Integration with BI Tools: Aggregated data is often more compatible with various business intelligence (BI) tools, enabling seamless integration for reporting and analysis purposes.
Foundation for AI Analytics: Aggregated data sets provide a foundation for predictive modeling and forecasting, enabling your organization to plan for the future based on historical trends and patterns.
Types of Data Aggregation
There are several ways that data is aggregated, but time, spatial, and attribute aggregation are the 3 primary types:
1) Time aggregation refers to gathering all data points for one resource over a specific period of time. For example, grouping data points based on time intervals, such as yearly, monthly, weekly, daily, or hourly. Aggregation by date is related to this, allowing trends to be shown over a period of years, quarters, months, etc.
2) Spatial aggregation involves collecting all data points for a group of resources over a given time period. For example, calculating the total number of visitors or leads across all marketing channels.
3) Attribute aggregation is when data is summarized based on specific attributes or categories, such as customer segment, job title, or product category.
Manage Quality and Security in the Modern Data Analytics Pipeline
Data Aggregation Process
Overall, the process involves combining and summarizing large sets of data into a single format and more manageable and understandable form. Atomic level data rows are replaced by totals or summary statistics through the computation of statistics or derived values. This results in a condensed representation of the original dataset.
Your first process decision is in choosing to go manual vs automated:
- Manual aggregation involves collecting and summarizing information from various data sources by human intervention, often using tools like spreadsheets or manual calculations. It requires you to personally gather, organize, and compute data, which can be time-consuming and potentially prone to human error. See the Methods section below for the many types of analysis you can perform.
- Automated aggregation refers to the process of systematically collecting, organizing, and summarizing large volumes of data using software or specialized tools, without the need for manual intervention. This method streamlines the aggregation process, reduces human error, and allows for faster and more efficient data analysis.
Today, most companies employ an automated approach, using a data aggregator tool as a part of an integration platform as a service (iPaaS). See the next section for a detailed look at the process using a data aggregator tool.
Data Aggregation Tools
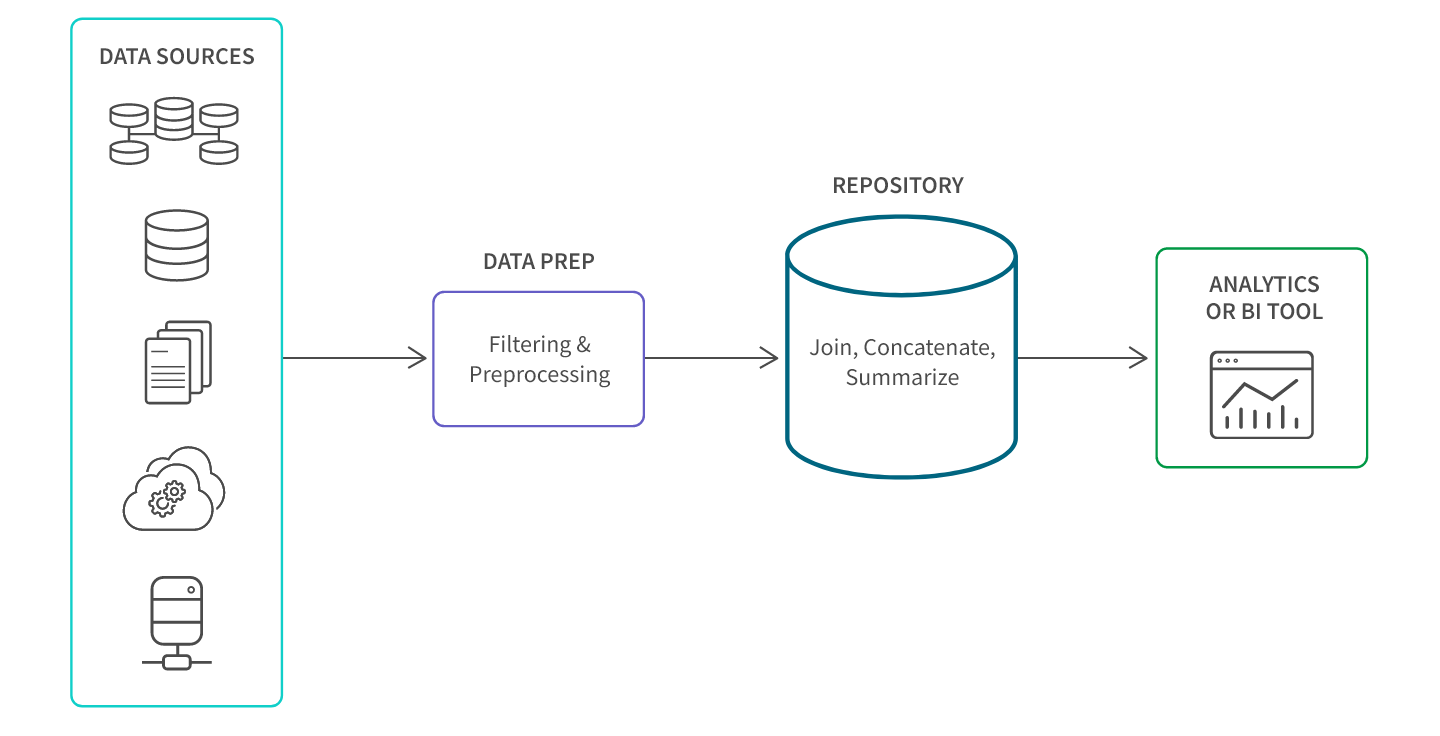
Data aggregation is typically performed using a data aggregator tool as part of your overall data management process. These tools operate through the following steps:
Data Collection
- Collecting data from diverse data sources like databases, apps, spreadsheets, IoT devices, ad platforms, website analytics software, and social media. This can include real-time data streaming.
Preparation & Cleansing
- Performing filtering and preprocessing to eliminate inconsistencies, errors, or invalid values before loading the data into a repository such as a data warehouse. These processes bolster the quality of your data, ultimately leading to more dependable and trustworthy insights and analysis.
Aggregation
- Applying normalization techniques or predefined algorithms to standardize the data (see Methods section above).
- Additionally, certain tools may employ predictive analytics, AI and machine learning to forecast trends or performance.
Analysis and Presentation
- Analyzing the aggregate data to generate fresh insights.
- Displaying the aggregated data in a concise summary format.
Whether you’re using a manual or automated process, you’ll perform one or more of the various aggregation methods below.
Summation: Adds up numerical values to calculate a total or aggregate value.
Counting: Determines the total number of data points in a dataset.
Average (Mean): Calculates the central value by adding up all data points and dividing by the total count.
Minimum and Maximum: Identifies the smallest and largest values in a dataset, respectively.
Median: Finds the middle value in a sorted dataset, dividing it into two equal halves.
Mode: Identifies the most frequently occurring value in a dataset.
Variance and Standard Deviation: Measure the spread or dispersion of data points around the mean.
Percentiles: Divide the data into hundred equal parts, helping to understand the distribution of values.
Aggregating by Time Intervals: Groups data based on specific time periods (e.g., hours, days, months) to analyze trends over time.
Weighted: Applies different weights to data points based on their importance or significance.
Geospatial: Combines data based on geographic locations or regions.
Hierarchical: Aggregates data in a hierarchical structure, allowing for summaries at different levels of granularity.
Rolling: Calculates aggregate values over a moving window or a specific range of data points.
Cumulative: Computes running totals or cumulative sums over a sequence of data points.
These methods allow analysts and data scientists to extract meaningful insights from large and complex datasets, facilitating informed decision-making and trend analysis.
Examples
Here are some examples illustrating how condensing large sets of data into meaningful summaries is applied across various contexts.
- Finding the average temperature for a month in a particular city.
- Aggregating customer reviews to calculate an overall rating for a product.
- Determining the highest and lowest scores in a set of exam results.
- Summing up the number of website visitors by country.
- Grouping and totaling customer data such as the number of product sales by category.
- Finding the median income for households in a specific region.
- Calculating the total number of social media interactions for a marketing campaign.
- Aggregating daily stock prices to calculate weekly or monthly averages.
- Summarizing website click-through rates for different marketing channels.
These use cases show how aggregation can help you make more informed decisions about real-world challenges such as optimizing marketing programs, setting prices, and making operations more efficient.
Frequently Asked Questions
What is the difference between data aggregation vs data mining?
Data aggregation involves summarizing and condensing large datasets into a more manageable form, while data mining focuses on discovering patterns, trends, and insights within data to extract meaningful information and make predictions. In essence, it simplifies data, while data mining explores it for valuable knowledge.
What are data aggregators?
Data aggregators are entities or tools that collect, compile, and organize large volumes of data from different sources into a centralized repository, providing a simplified and comprehensive view for analysis and decision-making. They play a crucial role in simplifying complex data for further processing and insights extraction.
Who is involved in data aggregation?
Data aggregation typically involves data analysts, scientists, or specialized software tools that systematically collect and process large volumes of data from various data sources. Additionally, domain experts and stakeholders who require summarized information for business decisions may also be involved in the process.
What is an example of data aggregation?
An example of aggregation is data from clinical trials that examines and summarizes the impact of a drug on different segments of a population.
Make even the toughest data challenges easy


