Streaming Database
What it is, how it works, challenges, and best practices. This guide provides practical advice to help you understand and manage streaming databases.
What is a Streaming Database?
A streaming database is a data repository designed to consume, store, process, and enrich real-time data as it is generated. Real-time data is information that is passed from source to consuming application, ideally with no delay. Bottlenecks in your data infrastructure or bandwidth can create a lag and this underscores the importance of a robust streaming database architecture.
How It Works
Streaming data involves real-time processing of data from up to thousands of sources such as sensors, financial trading floor transactions, e-commerce purchases, web and mobile applications, social networks and many more.
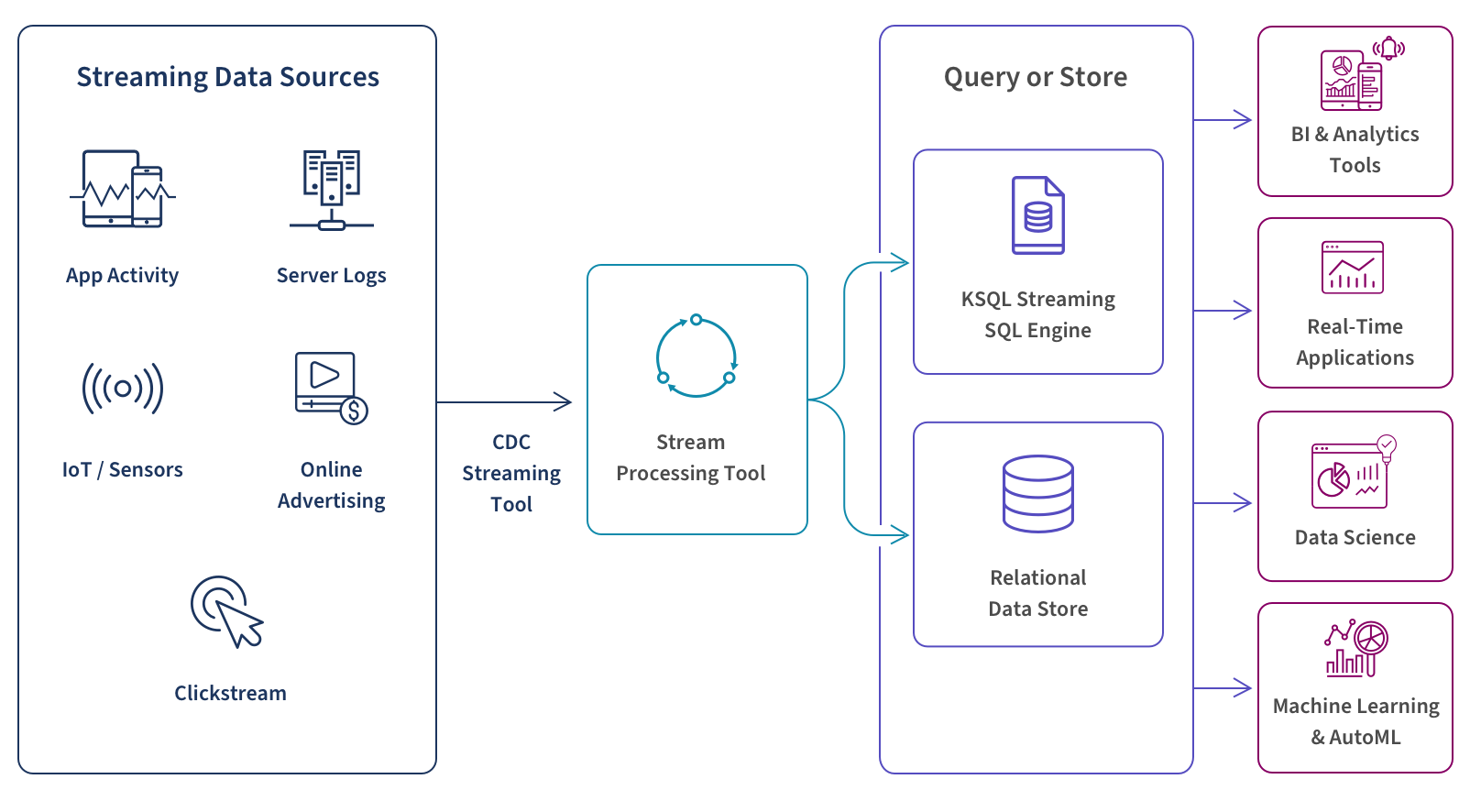
You can choose to perform real-time queries, store your data, or both. At this stage, your streaming database infrastructure must filter, aggregate, correlate, and sample your data using tools such as Google BigQuery, Snowflake, Dataflow, or Amazon Kinesis Data Analytics. To query the real-time data stream itself, you can use a streaming SQL engine for Apache Kafka called ksqlDB. To store this data in the cloud for future use you can use a streaming database or cloud data warehouse such as Amazon S3, Amazon Redshift, or Google Storage.
Finally, by aggregating and analyzing these real-time data streams, you can use real-time analytics to trigger downstreaming applications, gain in-the-moment business insights, make better-informed decisions, fine-tune operations, improve customer service and act quickly to take advantage of business opportunities.
Streaming Change Data Capture
Learn how to modernize your data and analytics environment with scalable, efficient and real-time data replication that does not impact production systems.
Streaming Database and Apache Kafka
Streaming databases require a sophisticated streaming architecture and Big Data solution like Apache Kafka. Kafka is a fast, scalable and durable publish-subscribe messaging system that can support data stream processing by simplifying data ingest. Kafka can process and execute more than 100,000 transactions per second and is an ideal tool for enabling database streaming to support Big Data analytics and data lake initiatives.
But using Kafka for database streaming can create a variety of challenges as well. Source systems may be adversely impacted. A significant amount of custom development may be required. And scaling efficiently to support a large number of data sources may be difficult.
Popular database streaming resources
Real-time Data Ingestion and CDC Streaming
Real-time data ingestion and CDC streaming software allows you to aggregate all your data sources. They offer integration solutions for the broad array of platforms and address the challenges of data ingestion and data replication in databases, data warehouses, Hadoop and SAP, as well as Kafka and other real-time messaging systems. The best solutions are designed for data residing on premises or in the cloud, as well as on legacy mainframe systems.

Replication software simplifies real-time data ingestion in Kafka to deliver significant benefits for database streaming.
- Enables real-time data capture by feeding live database changes to Kafka message brokers with low latency.
- Administrators can use an intuitive and configurable graphical user interface to easily set up data feeds with no manual coding.
- Minimizes the impact of database streaming with log-based change data capture technology and a unique zero-footprint architecture that eliminates the need to install intrusive agents, triggers or timestamps on sources and targets.
- Provides an architecture and software that can scale to ingest data from thousands of databases.
In addition to Kafka, the best replication tools enable database streaming to Confluent, Amazon Kinesis, Azure Event Hub and MapR-ES.
DataOps for Analytics
-

Real-Time Data Streaming (CDC)
Extend enterprise data into live streams to enable modern analytics and microservices with a simple, real-time and universal solution. -

Agile Data Warehouse Automation
Quickly design, build, deploy and manage purpose-built cloud data warehouses without manual coding. -

Managed Data Lake Creation
Automate complex ingestion and transformation processes to provide continuously updated and analytics-ready data lakes.