Data Vault
What it is, why you need it, and best practices. This guide provides definitions and practical advice to help you understand and establish a modern data vault.
What is a Data Vault?
A data vault is a data modeling approach and methodology used in enterprise data warehousing to handle complex and varying data structures. It combines the strengths of 3rd normal form and star schema. This hybrid approach provides a flexible, agile, and scalable solution for integrating and managing large volumes of data from diverse sources to support enterprise-scale analytics.
Data Vault Modeling
Data vaults have 3 types of entities: Hubs, Links, and Satellites.
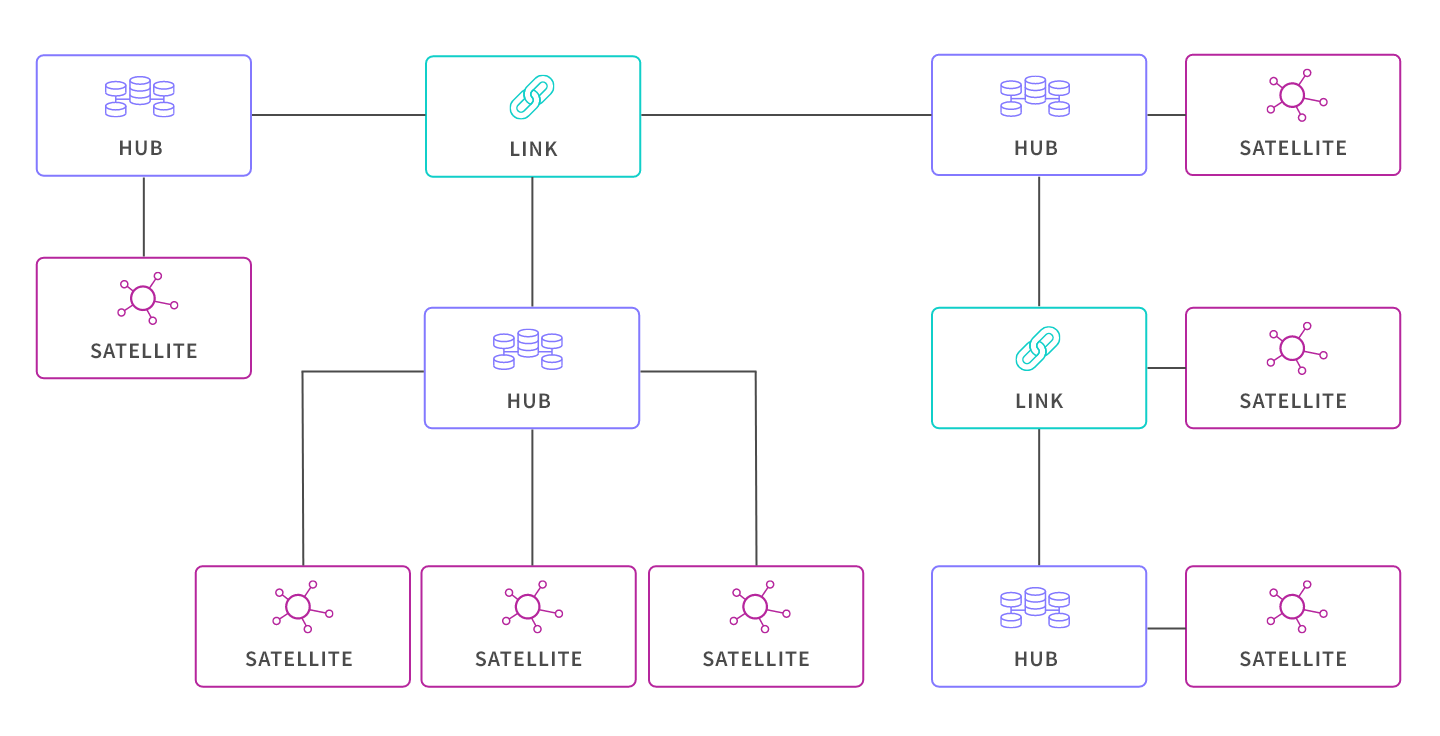
Hubs:
- Represent core business entities like customers, products, or stores.
- Contain the business key and essential fields.
- Do not hold contextual or detailed entity information.
- Maintain a one-row-per-key constraint, ensuring that each key is associated with only one entry.
Links:
- Establish relationships between different business entities.
- Connect hubs to illustrate associations between entities.
- Help capture how entities relate to each other in a structured manner.
Satellites:
- Store descriptive attributes related to the business entities in hubs (these can change over time, similar to a Kimball Type II slowly changing dimension).
- Contain additional information like timestamps, status flags, or metadata.
- Provide context and historical data about the entities over time.
Benefits
A Data Vault (DV) provides you a robust foundation for building and managing enterprise data warehouses, especially in scenarios where data sources are numerous, diverse, and subject to change.
The benefits of using a this modeling technique include:
Flexibility: DV’s are based on agile methodologies and techniques, so they’re designed to handle changes and additions to data sources and business requirements with minimal disruption. This makes them well-suited for environments with evolving data requirements, such as adding or deleting columns, new tables, or new/altered relationships.
Scalability: DV’s can accommodate large volumes of data (up to PBs volumes) and support the integration of data from a wide range of sources. As such, this model is a great fit for organizations implementing a data lake or data lakehouse.
Auditability: They maintain a complete history of the data, making it easier to track changes over time and meet HIPAA compliance and other auditing requirements and regulations.
Ease of Maintenance: They simplify the process of incorporating new data sources or modifying existing ones, reducing the time and effort required for maintenance. For example, there's less need for extensive refactoring of ETL jobs when the model undergoes changes. Plus, this approach simplifies the data ingestion process, removes the cleansing requirement of a Star Schema.
Parallelization: Data can be loaded in parallel, allowing for efficient processing of large datasets.
Ease of Setup: They have a familiar architecture–employing data layers, ETL, and star schemas–so your teams can establish this approach without extensive training.
Data Vault Architecture
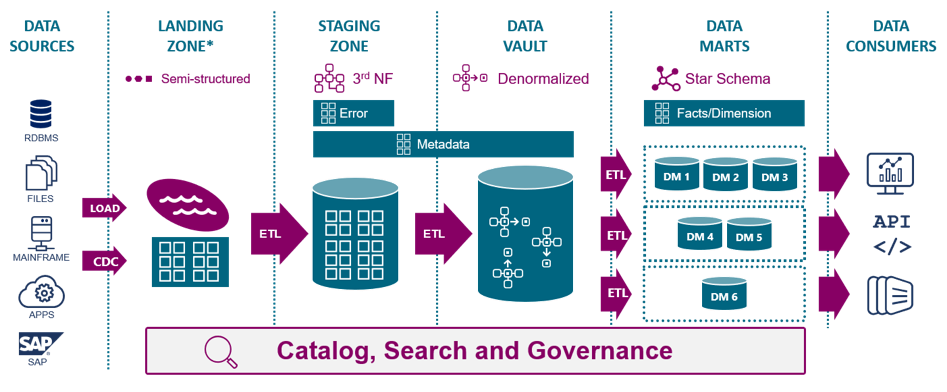
Let’s walk through the diagram above.
- Data from source systems such as transactional, supply chain, and CRM applications is either batch loaded or streamed real-time using CDC.
- It’s important for your data integration system to have robust catalog, search, and data governance capabilities to support this entire process.
- This semi-structured data is placed in a landing zone such as a data lake.
- It is then extracted, transformed, and loaded (ETL) as Inmon’s relational 3rd normal form data into a staging zone (or “Raw Data Vault”) repository such as a data warehouse.
- ETL is performed again to bring denormalized data into the Data Vault model.
- ETL processes are performed on an as-needed basis to load this data into star schema formatted (dimensional model) data marts.
- Data consumers can then access relevant, structured data for use cases such as analytics, visualizations, data science, and APIs to trigger alerts and actions in other systems.

Data Lake or Data Warehouse?
Answer 12 key questions to unlock the right answer for you.
Data Vault 2.0
Data Vault 2.0 is an open source extension and refinement of Data Vault 1.0. Here are key facts:
- Introduced by Dan Linstedt and Michael Olschimke in 2013
- Maintains the hub-and-spoke architecture
- Introduces additional features and best practices
- Encourages the use of advanced technologies like big data platforms, cloud computing, and automation tools to enhance data management capabilities
- Introduces a new architecture that includes a persistent staging area, a presentation layer in data marts, and data quality services:
- Raw vault: Contains the original source data
- Business vault: Contains business rules and transformations applied to the raw vault
- Information mart: Presentation layer providing analytical capabilities
- Data mart: Presentation layer providing reporting capabilities to end users
How a Data Vault Solves 5 Key Enterprise Data Warehouse (EDW) Challenges
Challenge #1: Adapting to constant change.
DV Solution: Through the separation of business keys (as they are generally static) and the associations between them from their descriptive attributes, a Data Vault (DV) confronts the problem of change in the environment. Using these keys as the structural backbone of a data warehouse all related data can be organized around them. These Hubs (business keys), Links (associations), and SAT (descriptive attributes) support a highly adaptable data structure while maintaining a high degree of data integrity. Dan Linstedt often correlates the DV to a simplistic view of the brain where neurons are associated with Hubs and Satellites and where dendrites are Links (vectors of information). Some Links are like synapses (vectors in the opposite direction). They can be created or dropped on the fly as business relationships change, automatically morphing the data model as needed without impacting the existing data structures.
Challenge #2: Really big data.
DV Solution: Data Vault 2.0 arrived on the scene in 2013 and incorporates seamless integration of big data technologies along with methodology, architecture, and best practice implementations. Through this adoption, very large amounts of data can easily be incorporated into a DV designed to store using products like MongoDB, NoSQL, Apache Cassandra, Amazon DynamoDB, and many other NoSQL options. Eliminating the cleansing requirements of a star schema design, the DV excels when dealing with huge data sets by decreasing ingestion times, and enabling parallel insertions which leverages the power of big data systems.
Challenge #3: Complexity.
DV Solution: Crafting an effective and efficient DV model can be done quickly once you understand the basics of the 3 table types: Hub, Satellite, and Link. Identifying the business keys 1st and defining the Hubs is always the best place to start. From there Hub-Satellites represent source table columns that can change, and finally Links tie it all up together. Remember it is also possible to have Link-Satellite tables too. Once you’ve got these concepts, it’s easy. After you’ve completed your DV model the next common thing to do is build the ETL data integration process to populate it. While a DV data model is not limited to EDW/BI solutions, anytime you need to get data out of some data source and into some target, a data integration process is generally required.
Challenge #4: The Business Domain (fitting the data to meet the needs of your business, not the other way around).
DV Solution: The DV essentially defines the Ontology of an Enterprise in that it describes the business domain and relationships within it. Processing business rules must occur before populating a Star Schema. With a DV, you can push them downstream, post EDW ingestion. An additional DV philosophy is that all data is relevant, even if it is wrong. Dan Linstedt suggests that data being wrong is a business problem, not a technical one. We agree! An EDW is really not the right place to fix (cleanse) bad data. The simple premise of the DV is to ingest 100% of the source data 100% of the time; good, bad, or ugly. Relevant in today’s world, auditability and traceability of all the data in the data warehouse thus become a standard requirement. This data model is architected specifically to meet the needs of today’s EDW/BI systems.
Challenge #5: Flexibility.
DV Solution: The DV methodology is based on SEI/CMMI Level 5 best practices and includes many of its components combining them with best practices from Six Sigma, TQM, and SDLC (Agile). DV projects have short controlled release cycles and can consist of a production release every 2 or 3 weeks automatically adopting the repeatable, consistent, and measurable projects expected at CMMI Level 5. When new data sources need to be added, similar business keys are likely, new Hubs-Satellites-Links can be added and then further linked to existing DV structures without any change to the existing data model.
DataOps for Analytics
Modern data integration delivers real-time, analytics-ready and actionable data to any analytics environment, from Qlik to Tableau, Power BI and beyond.
-

Real-Time Data Streaming (CDC)
Extend enterprise data into live streams to enable modern analytics and microservices with a simple, real-time and universal solution. -

Agile Data Warehouse Automation
Quickly design, build, deploy and manage purpose-built cloud data warehouses without manual coding. -

Managed Data Lake Creation
Automate complex ingestion and transformation processes to provide continuously updated and analytics-ready data lakes.