
Data Lake Architecture
What it is, key features, and benefits. This guide provides a definition and practical advice to help you understand data lake architecture.
Data Lake Architecture Guide
Modern vs Traditional Architecture
The modern data lake architecture provides rapid data access and analytics by having all necessary compute resources and storage objects internal to the data lake platform. Traditional data lake architectures offered slower performance by storing data in an external data repository that needed to be replicated to another storage-compute layer for analytics.
Data Lake Definition
A data lake is a data storage strategy that consolidates your structured and unstructured data from a variety of sources. This provides a single source of truth for different use cases such as real-time analytics, machine learning, big data analytics, dashboards, and data visualizations to help you uncover insights and make accurate, data-driven business decisions.
Here six main advantages of a data lake vs data warehouse:
- Scale. A data lake's lack of structure lets it handle massive volumes of structured and unstructured data.
- Speed. Your data is available for use much faster since you don’t have to transform it or develop schemas in advance.
- Agility. Your data lake supports both analytics and machine learning and you can easily configure data models, queries, or applications without pre-planning.
- Real-time. You can perform real-time analytics and machine learning and trigger actions in other applications.
- Better insights. You’ll gain previously unavailable insights by analyzing a broader range of data in new ways.
- Lower cost. Data lakes are less time-consuming to manage and most of the tools you use to manage them are open source and run on low-cost hardware or cloud services.
Ultimately, a data lake can transform your organization’s use of data and democratize access to data, improving data literacy for all. Learn more about data lakes.
Data Lake Architecture
Data lakes employ a flat architecture, allowing you to avoid pre-defining the schema and data requirements and instead store raw data at any scale without the need to structure it first. You achieve this by using tools to assign unique identifiers and tags to data elements so that only a subset of relevant data is queried to analyze a given business question.
These tools, such as Snowflake, Azure, AWS, and Hadoop, vary in specific capabilities. Therefore, your system’s detailed physical structure will depend on which tool you select.
High-level data lake architecture diagram:
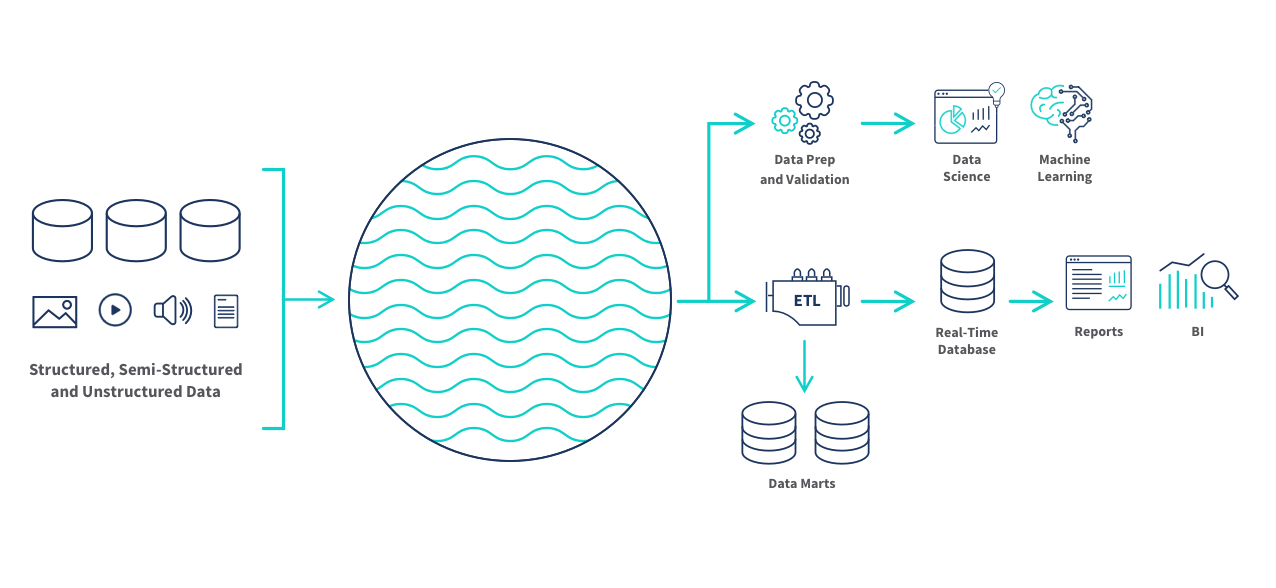
Your data teams can build ETL data pipelines and schema-on-read transformations to make data stored in a data lake available for data science and machine learning and for analytics and business intelligence tools. Or, managed data lake creation tools help you achieve this without the limitations of slow, hand-coded scripts and scarce engineering resources.
Modern data lake architectures are cloud-based and provide rapid data access and analytics by having all necessary compute resources and storage objects internal to the data lake platform. They also isolate workloads and allocate resources to the prioritized jobs, helping you avoid user concurrency issues from slowing down analyses across your organization. Here are the key features of a cloud data lake architecture:
- Simultaneous data loading and querying without impacting performance
- Independent storage resource and compute scaling
- An architecture which is multi-cluster and shared-data
- Metadata capabilities that are core to the object storage environment
- No performance degradation from adding users
Cloud Data Lake Comparison Guide
Get an unbiased, side-by-side look at all the major cloud data lake vendors, including AWS, Azure, Google, Cloudera, Databricks, and Snowflake.
Challenges
You want to make use of the massive amounts of data that are coming from a wide variety of data sources. Here are the key challenges you’ll face in your data lake architecture:
Query performance is often limited with concurrency and scalability issues. Also, a complex architecture can result in broken data pipelines, performance degradation (such as slow transformation), and error-prone data movement outside of your data lake. These errors, plus a rigid architecture can result in governance and security risks.
The last, but not least, challenge is data ingestion. Ingesting and integrating data from hundreds or even thousands of diverse sources can be overwhelming. When moving information to a data lake, many sources require custom coding and individual agents. This can quickly drain your IT resources. Moving data to a data lake can also have a negative impact on source systems, causing disruption and loss of data availability. Big data analytics tools that have universal and real-time data ingestion capabilities can speed and simplify ingestion of data from a wide variety of data sources, including live data streams.
Managed Data Lake Creation
As stated above, a key challenge in deploying a data lake is that traditional data integration processes are limited by slow, hand-coded scripts and scarce engineering resources.
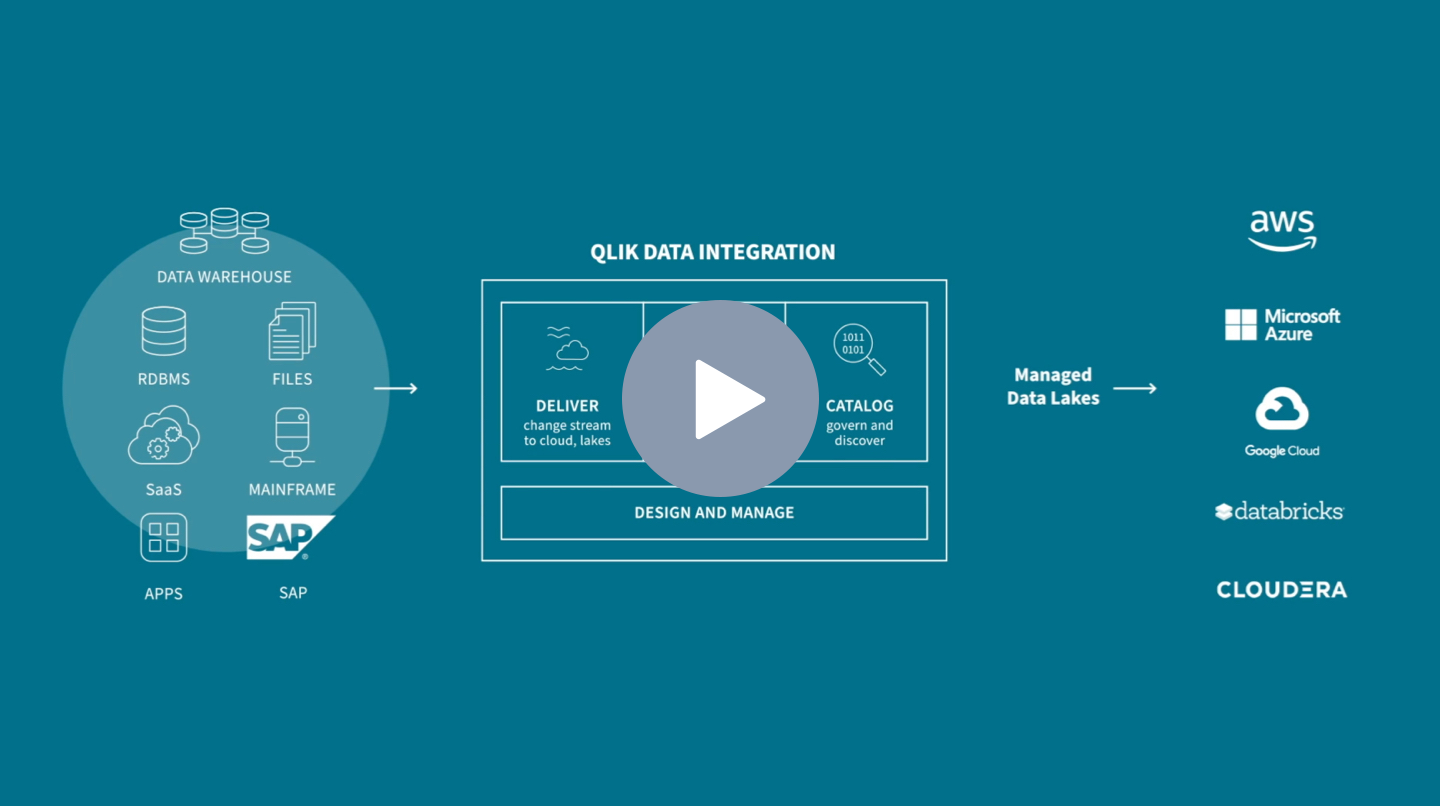
Managed data lake creation offers a fully automated approach to end-to-end data lake or data lakehouse creation. This automates your entire data lake pipeline, from real-time ingestion to processing and refining raw data and making it available to consumers.
The best solutions allow you to easily build and manage agile data pipelines with support for all major data sources and cloud targets without writing any code. They also offer zero-footprint change data capture technology that delivers data in real-time without impacting your production systems and end-to-end lineage, so you can fully trust your data.
Lastly, your data lake should have a secure enterprise-scale data catalog that provides data consumers with a governed data marketplace to search, understand and shop for curated data.
Learn more about managed data lake creation.
3 Ways to Increase Your Data Lake ROI
Snowflake Cloud Data Lake Platform
Snowflake’s cloud data platform provides accessibility, performance and scale to complement your data lake. As shown below, you can mix components of date lake patterns.
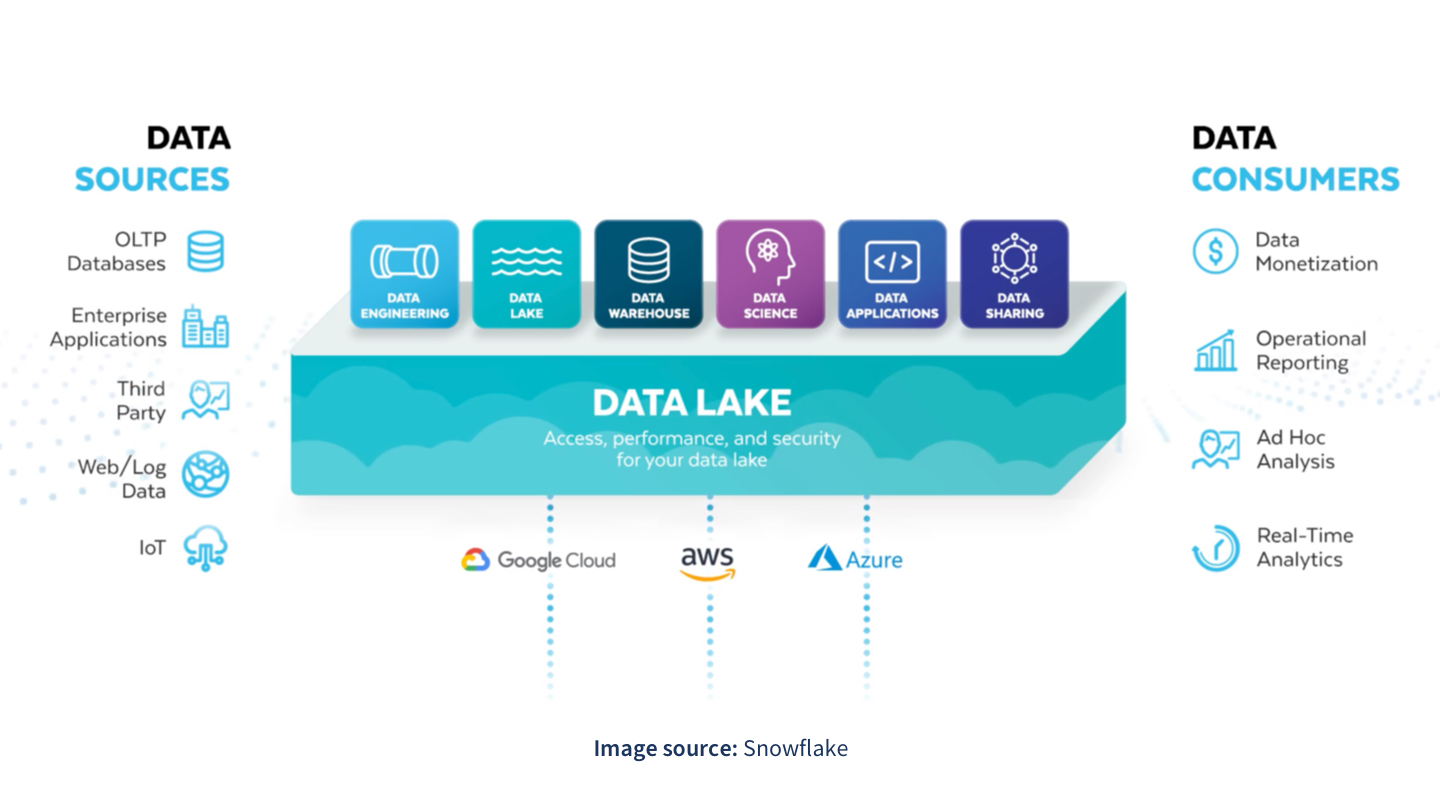
Here are the key benefits of Snowflake:
- You can query data directly over your data lake with unlimited elastic scalability and no resource contention or concurrency issues. This brings accelerated analytics and unlimited scale.
- Data engineers can work with a streamlined architecture to run reliable and performant data pipelines.
- Snowflake has built-in governance and security, so all your users can access all data in the data lake with granular-level access and privacy control.
- It’s offered as a service with zero maintenance, hardware, or infrastructure to manage.
- Snowflake can also be used as a full data lake for all your data and all users.
To take full advantage of Snowflake and ease implementation, you’ll need world class data ingestion.
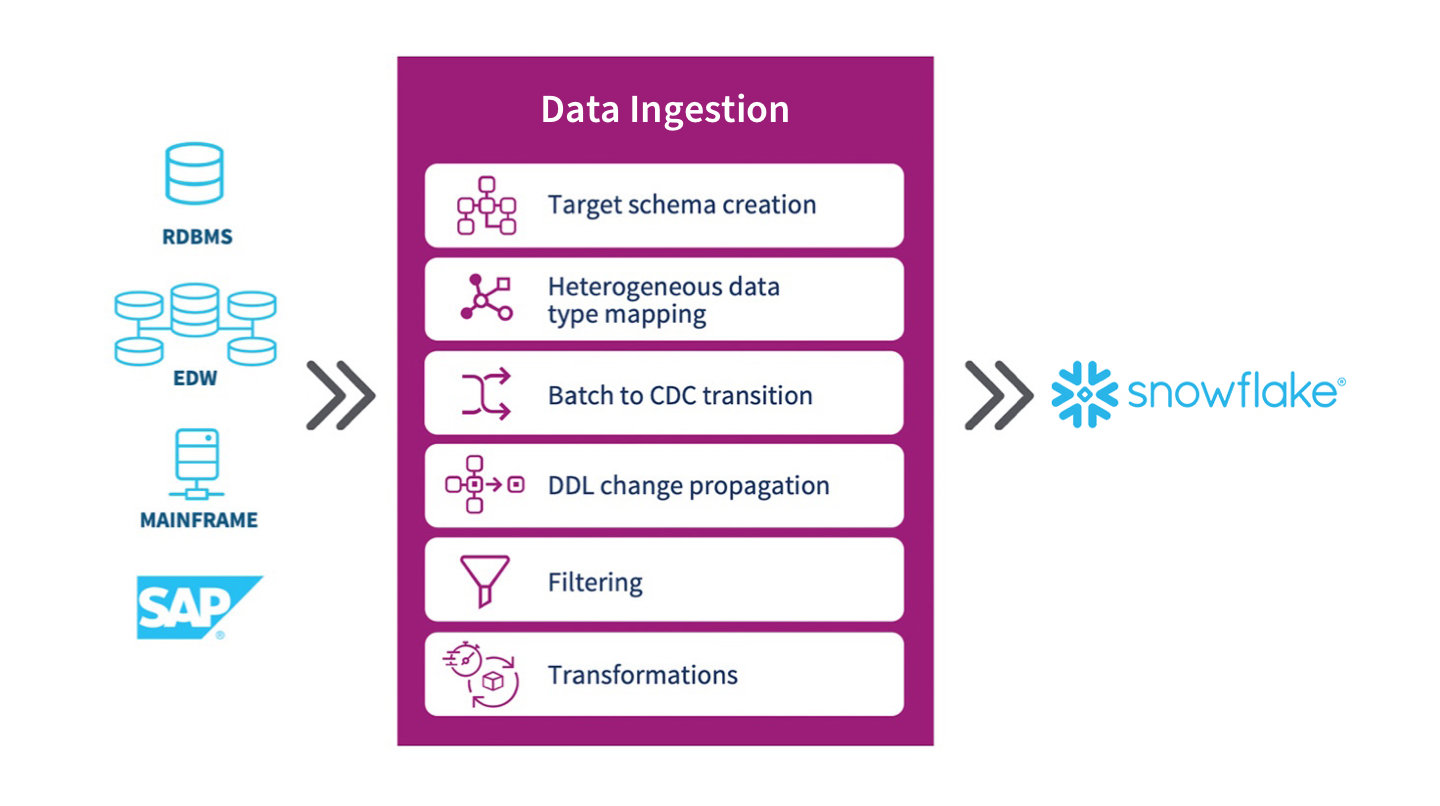
Top data ingestion tools allows you to continuously ingest data from multiple sources to your Snowflake platform with zero downtime and in real-time. They also bring change data capture (CDC) technology that ensures that you’re always working with real-time data while streamlining operations and minimizing the impact on production systems.
Learn more about ingestion into Snowflake.
DataOps for Analytics
Modern data integration delivers real-time, analytics-ready and actionable data to any analytics environment, from Qlik to Tableau, Power BI and beyond.
-

Real-Time Data Streaming (CDC)
Extend enterprise data into live streams to enable modern analytics and microservices with a simple, real-time and universal solution. -

Agile Data Warehouse Automation
Quickly design, build, deploy and manage purpose-built cloud data warehouses without manual coding. -

Managed Data Lake Creation
Automate complex ingestion and transformation processes to provide continuously updated and analytics-ready data lakes.